- 상태란
- 클래스 변수 혹은 인스턴스 변수
- 함수가 상태를 갖고 있느냐를 따질 때는 함수 외부에서 영향이 있는지
- 함수와의 디펜던시가 있으면 테스트 코드 짜기가 어려워짐.
- 상태가 없는 함수 = 순수 함수
- 매개변수에 의해 상태가 있을 수 있다.
- 결국 외부 요인이 작용할 수 있다고 하면 상태가 있다고 본다.
- 테스트 관점과 멀티스레드 관점에서 상태값을 이해하고 있어야 한다.
- 함수형 프로그래밍
- 부수효과를 없애고 순수 함수를 만들어 모듈화 수준을 높이는 프로그래밍 패러다임
- 주어진 값 이외의 외부 변수 및 프로그램이 실행에 영향을 끼치지 않아야 된다는 의미, 부수효과를 만족하는 함수를 순수함수라고 한다.
- 순수함수 : 모든 입력이 입력으로만, 모든 출력이 출력으로만 사용.
- 변경 가능한 데이터 및 사이드 이팩트를 피하는 기본 원칙에 따라 소프트웨어를 구성하는 프로그래밍 패러다임.
- NPE의 정확한 의미?
- 스택 영역에 변수가 저장되는데, primitive과 referece가 저장될 수 있다.
- 여기서 primitive는 값이 저장되지만 referecne는 주소가 저장된다. 주소가 저장되어 있어야 하는데, 주소를 가르키고 있지 않으면 해당 예외가 발생한다.
- 스택에 GC가 없는 이유?
- 힙은 정확히 언제 해제될지 모르니까 GC가 있는 것이고
- 스택은 언제 스텍 프레임이 해제되는지 명확하니까 굳이 필요 없는거다.
- wait과 notify는 결국 모니터락 관점에서 생각해야 한다.
- wait는 모니터락을 내려놓게 하는것이고
- notify는 다른 스레드가 락을 가질 수 있도록 깨우는 것이다.
- 인터페이스와 추상클래스의 가장 큰 차이
- 상태값 존재 여부가 가장 큰 차이이다
- 상수는 포함할 수 있지만, 내부변수는 가질 수 없다.
- 행위만 주겠다고 하면 인터페이스를 쓰는게 맞다
- 행위와 상태값을 가지고 있으면 추상클래스를 쓰는게 낫다
- 디폴트 메소드는 오버라이드 하지 않아도 에러가 나지 않도록 하기 위함이다
- Mixin은 디폴트 implementation을 통해서 구현하는 경우가 있다.
- Mutable과 Unmutable이란?
- 메모리에 올라간 후 값이 바뀔 수 있는지 없는지 여부
- Final
- final은 ummutable한 성질을 항상 보장할 수 있는가? -> NO
- 타입마다 다르다, primitive는 보장하지만, reference는 참조하고 있는 객체가 가지고 있는 인스턴스 변수는 바뀔 수 있다.
- 따라서 final
- 예외처리 전략
- checked Exception은 try로 감싸거나, thorwable로 선언
- 스프링에서는 익셉션 핸들러에서 제한된다.
- 미리 만들어놓은 익셉션으로 변환해서 처리한다.
- Unchecked Exception종류가 너무 많아 수를 줄이기 위해서 미리 만들어 놓는 것이다.
- 구아바 라이브러리에 Thorwoabels라이브러리를 통해 cause chaning에서 root cause를 리턴해줄 수 있다.
- 클래스 변수와 인스턴스 변수는 JVM 상에서 어떻게 저장되는가?
- 클래스 변수는 메소드 영역에 저장되고, 인스턴스 변수는 힙 영역에 저장된다.
- 스태틱을 난발했을 때 문제점?
- 객체지향 관점에서 클래스간의 응집력을 떨어뜨리게 된다.
- 레퍼런스가 끊길 수 없어서 스태틱 변수에 들어가 있는 배열은 GC가 발생하지 않아 메모리 누수가 발생한다.
- 대표적인 안티패턴
- 메소드란?
- 클래스에서 어떤 특정 작업을 수행하기 위한 명령문의 집합
- 구성요소
- 제어자
- 리턴타입(필수)
- 메소드이름(필수)
- 예외목록
- 메소드 내용(필수)
- 메세지 : 메소드에서 다른 메소드를 호출할 대 전달하는 값. 매개변수들이 여기에 속한다.
- 상속 : 부모에 선언된 변수와 메소드에 대한 사용권을 갖는 것. 클래스 선언시 extends를 사용하여 확장하거나, implements를 사용하여 구현한 경우
- 다형성 : 부모 클래스에서 파생된 자식 클래스들의 기능이 각기 다를 수 있다는 성질
- 상수풀?
- 클래스란?
- 예약어
- 자바에 등로고디어 있고, 시스템과 사용자간에 약속되어 있는 단어.
- 추상 클래스 : 하나 이상의 추상 메서드를 포함하는 클래스
- 인스턴스화 불가능
- 추상 메서드 는 pirvate 키워드 선언 불가.
- 상속을 강제하기 위해 사용함
- 주석
- 한줄 주석 :
- 블록 주석 : 여러 줄을 한꺼번에 주석처리할 때 사용됨
- 문서용 주석 : 클래스 선언 바로 앞이나, 메소드 선언 바로 앞에 있으면 문서용 주석으로 인식되어 처리된다.
- 객체지향이란
- 명령어의 목록으로 보는 시각에서 벗어나 여러개의 독립된 단위인 객체들의 모임으로 파악하고자 하는 패러다임
- 4대 특성(캡상추다)
- 캡슐화
- 변수와 함수를 하나의 클래스로 묶는 것
- 불필요한 정보는 숨기고 중요한 정보만을 표현함.
- 공통의 속성이나 기능을 묶어 이름을 붙이는 것
- 목적 : 코드의 재수정 없이 재사용 하는것.
- 은닉 : 세부 구현을 외부로 드러내지 않도록 특정 모듈 내로 숨기는 것. 외부로의 노출을 최소화 하여 모듈 간의 결합도를 떨어뜨려 유연함과 유지보수성을 높이는 개념
- 상속
- 부모 클래스의 속성과 기능을 그대로 이어받아 사용할 수 있게끔 하고 기능의 일부분은 다시 재정의하여 사용할 수 있게 하는 것.
- 재활용으로 인한 생산성과 유지보수성이 좋다.
- 추상화
- 어떤 실체로부터 공통적인 부분이나 특성들을 한 곳에 모은 것을 의미함.
- 다형성
- 하나의 함수명이 상황에 따라 다른 의미로 해석될 수 있는 특징
- 오버라이딩
- 부모클래스의 메소드와 같은 이름, 매개변수를 재정의 하는 것
- 오버로딩 : 같은 이름의 함수를 여러개 정의하고, 매개변수 타입, 갯수, 순서 를 다르게 하여 호출할 수 있는 것
- 캡슐화
- 자바의 특징
- 단순하고 객체지향적이다
- 견고하고 보안상 안전하다
- 아키텍처에 중립적이고 포터블해야한다
- 높은 성능을 제공해야 한다
- 자바는 인터프리터 언어이며, 스레드를 제공하고 동적인 언어다
- 변수
- 자료형
- 연산자
- 조건 제어문
- 스위치
- label
- 배열
- 참조자료형
- this
- 오버로딩
- static 메소드, 일반메소드 차이
- static 블록
- Pass by value, Pass by reference
- 매개변수 지정
- 패키지
- 접근 제어자(아래 순서대로 좁아짐
- public : 해당 객체를 사용하는 프로그램 어디서나 직접 접근 가능
- proteced : 동일 패키지 내 혹은 파생 클래스에머나 접근 가능.
- package-private (default) : 같은 패키지 내에서만 접근 가능함
- private : 해당 클래스 내에서만 가능함.
- 상속, 생성자
- 오버라이딩
- 부모 클래스의 메소드와 동일한 시그니처를 갖는 자식 클래스의 메소드가 존재할 때 성립
- Overriding 된 메소드는 부모 클래스와 동일한 리턴 타입을 가져야만 한다
- Overriding된 메소드의 접근 제어자의 부모 클래스에 있는 메소드와 달라도 되지만, 접근 권한이 확장되는 경우만 가능. 축소 되면 컴파일 에러 발생
- Overloading은 확장
- Overriding은 덮어쓰기, 부모 클래스의 메소드 시그니처를 복사해서 자식 클래스에서 새로운 것을 만들어 내어 부모 클래스의 기능은 무시하고 자식 클래스에서 덮어씀
- Polymorphism
- 폴리몰피즘. 상수 변수 객체 메소드등이 다양한 자료형에 속하는 것이 허가되는 성질.
- 같은 자료형에 여러가지 객체를 대응하여 다양한 결과를 얻어낼 수 있는 성질.
- 하나의 타입으로 다양한 결과를 얻을 수 있고, 객체를 모듈화 하여 보수를 용이하게 함.
- 구현하는 방법
- 오버로딩 : 매개변수로 다른 타입을 받아들여 결국엔 같은 기능을 수행하니 다형성이라고 할 수 있다.
- 오버라이딩 : 재정의 하여 부모 클래스의 함수를 호출하면 객체별로 재정의한 함수를 호출할 수 있음
- 형변환을 하더라도 실제 호출되는 것은 원래 객체에 있는 메소드가 호출됨.
- 자식 클래스에서 할 수 있는 일들
- 자식 클래스의 생성자가 호출되면 자동으로 부모 클래스의 매개변수가 없는 기본 생성자가 호출된다. 명시적으로 super()라고 지정 가능함.
- 부모 클래스의 생성자를 명시적으로 호출하려면 super()를 사용하면 된다
- 부모 클래스에 pirvate로 선언된 모든 변수가 자신의 클래스에 있는 것처럼 사용할 ㅅ ㅜ있다. 부모 클래스에 선언된 동일한 이름을 가지는 변수를 선언할 수 도 있다.
- 부모 클래스에 선언되어 있지 않는 이름의 변수를 선언할 수 도 있다.
- 변수처럼 부모 클래스에 선언된 메소드들이 자신으 ㅣ클래스에 선언된것처럼 사용할 수 있다.
- 부모 클래스에 선언된 메소드와 동일한 시그니쳐를 사용함으로써 메소드를 오버라이딩 할 수 있다.
- 부모 클래스에 선언되어 있지 않은 이름의 새로운 메소드를 선언할 수 있다.
- 참조형 자료도 형 변환이 가능하다
- 자식 타입의 객체를 부모 타입으로 형 변환하는 것은 자동으로된ㄷ .
- 부모 타입의 객체를 자식 타입으로 형 변환할 때에는 명시적으로 타입을 지정해줘야 한다. 부모 타입의 실제 객체는 자식 타입이어야 한다.
- instanceof 예약어로 객체의 타입을 확인할 수 있다.
- instanceof로 타입확인을 할 때 부ㅗ모 타입도 true라는 결과를 리턴한다
- 자바API : Application Progamming Interface.
- 패키지와 클래스 / 인터페이스 이름
- 클래스 상속 관계 다이어그램
- 부모 클래스에서는 선언되어있지만 자식 클래스에서 별도로 Overriding 하지 않은 메소드는 자세한 설명이 제공되지 않는다. 사용가능한 메소드가 있는데 그 클래스의 API가 없다면 부모 클래스들의 메소드를 살펴봐야 한다
- Deprecated : 사전적 의미는 강력히 반대하다.
- 생성자, 상수필드, 메소드에 선언되어 있음. 나중에 문제가 되거나, 혼란을 주면 Deprecated 처리 된다.
- 하위 호환성을 위해 그냥 없애버릴 수는 없어 컴파일 타임에 개발자에게 알려주는 것이다.
- 더 이상 사용하지 않기를 바라거나 안정성을 보장하지 않고 조만간 삭제될 API 등에서 사용
- 패키지와 클래스 / 인터페이스 이름
- java.lang.Object
- 모든 자바 클래스의 부모.
- 기본적으로 아무런 상속을 받지 않으면 해당 클래스를 상속 받음.
- 이중 상속은 안되지만여러번 여러 단계로 상속을 받을 수는 있다.
- 모든 클래스의 기본적인 행동들을 정의함.
- proteced Object clone() : 객체의 복사본을 만들어 리턴
- public boolean equals(Object obj) : 현재 객체와 매개변수로 넘겨받은 객체가 같은지 확인.
- protected void finalize() : 현재 객체가 더 이상 쓸모 없어졌을 때 가비지 컬렉터에 의해서 이 메소드가 호추ㄹ됨.
- public Class<?> getClass : 현재 객체의 Class 클래스의 객체를 리턴함
- public int hashCode : 객체에 대한 해시코드 값을 리턴함. 16진수로 제공되는 객체의 메모리 주소
- public String toString() : 객체를 문자열로 표현하는 값을 리턴함
- <스레드 처리를 위한 메소드>
- public void notify() 객체의 모니터에 대기하고 있는 단일 스레드를 깨운다.
- public void nofityAll() 객체의 모니터에 대기하고 있는 모든 스레드를 깨운다.
- public void wait() 다른 스레드가 현재 객체에 대한 notify() 메소드를 호출할 대 까지 현재 스데르가 대기하고 있도록 한다.
- public void wait(long imteout) : 위와 동일한데 매개변수에 지정한 시간만큼 대기한다. 시간이 니자면 다시 깨어난다.
- public void wait(long timeout, int nanos) 위와 동일한데 나노초 다누이까지 지정할 수 있다.
- toString()
- Object 클래스에서 가장 많이 쓰임
- System.out.println(), 객체에 대해 더하기 연산 이 두가지에 대해서 자동으로 호출된다.
- String을 제외한 참조자료형에 + 연산을 하면 자동으로 toString() 메소드가 호출되어 객체에 위치에는 String 값이 놓이게 된다.
- toString()을 했을 때 getClass().getName() + '@' + Integer.toHexString(hashCode())와 같은 효과이다.
- DTO를 사용할 때에는 toString()을 Overriding하는게 좋다. 사용할 때마다 출력하려고 하면 불편하기 때문에
- equals
- 객체는 ==만으로 같은지 확인이 되지 않는다. 참조자료형에서 사용하면 안된다 왜나하면 값이 아니라 주소값이기 때문이다.
- Overrding하지 않으면 hashCode() 값을 통해 비교한다.(해당 객체의 주소값을 리턴)
- 아래의 다섯개의 조건을 반드시 ㅁ나족해야 한다
- 재귀 : null 이 아닌 x라는 객체의 x.equls(x) 결과를 항상 true (당연) 자기자신은 자신과 같아야 한다
- .대칭 : null이 아닌 x, y가 있을 때 y.equlas(x)가 true면 x.equlas(y)도 true.
- 타동적 : x.equls(y), y.equls(z) -> ; z.equals(x) 여야 한다 (삼단 논법)
- 일관 : 객체가 변경되지 않으면 x.equls(y)는 결곽 ㅏ같아야 한다.
- nul과의 비교 : null이 아닌 x라는 객체의 x.euqls(null) 결과는 항상 false여야 한다
- hashCode,
- 객체의 주소값을 이용해 객체 고유의 해시 코드를 리턴하는 함수
- 객체의 메모리 주소인 16진수로 리턴한다. 두 객체가 동일하면 반드시 hashCode()값은 무조건 동일해야 한다.
- equals()를 오버라이드 하면 , hashcode()값은 무조건 동일해야만 한다.
- HashSet, HashMap, Hashtable과 같은 컬렉션에서 객체의 비교시 사용됨.
- 아래의 규칙을 만족해야함
- 동일한 객체면, 앱이 수행되는 동안 항상 동일한 int값을 리턴해야함
- 두 객체의 equals()가 트루면 hashCode() 값도 같아야 한다.
- 두 객체의 equals() 메소드를 사용하여 비교한 결과 false라고 해서 hashCode값이 무조건 다를 필요는 없다. 하지만 이 경우에 서로 다른 int값을 제공하면 hashtable에서 성능을 향상 시킴(같은 버킷에 저장하기 때문에)
- interface
- 메소드가 구현되어 있지 않음.
- 해당 메소드를 사용하는 입장에서는 내부 구현이 어떻게 되어있는지 궁금하지 않고, 원하는 메소드를 호출하고 그 답을 받으면 된다.
- 다형성의 장점이 있음. 상속 받은 클래스에서 재정의 하여 서로 다른 행동을 만들 수 있음.
- DAO(Data Access Object)패턴 : 이 패턴은 데이터를 저장하는 쩌장소에서 원하는 값을 요청하고 응답을 받는다
- Oracle이든, MongoDB든 작성한 메소드에서 결과만 제대로 넘겨주면 된다.
- 장점 :
- 설계시 선언만 해두면, 기능을 구현하는데에만 집중할 수 있다
- 개발자 역량에 따른 메소드 이름과 매개변수 선언의 객차를 줄일 수 있다.
- 공통적인 인터페이스와 abstract 클래스를 선언해놓으면 선언과 구현을 구분할 수 있다.
- interface는 상속이 아니라, 구냥 구현해야한다는 짐을 얹어 주는 것이다. 그냥 여러개의 짐을 얹어주는 것 뿐이다.
- abstract
- 일부 완성되어 있는 abstract 클래스. 클래스의 골격을 잡아줌.
- abstract 클래스는 클래스 선언 시 abstact 예약어를 클래스 앞에 추가하면 된다.
- 클래스 안에는 abstract으로 선언된 메소드가 0개 이상 있으면 된다.
- abstract 메소드가 하나라도 있으면 반드시 그 클래스는 abstract 클래스여야 한다.
- static, final이 있어도 된다. interface에서 있으면 안된다.
- 아주 공통적인 기능을 미리 구현해놓으면 도움이 된다.
- 여러 기존의 클래스에서 공통된 부분을 추상화 한것으로 클래스에게 구현을 강제화해서 구현을 위임
- final
- 상속을 해줄 수 없음.
- String 처럼 누군가 변경해서 사용하면 안되는 클래슬르 선언할 대 사용
- 메모드도 더이상 오버라이딩 할 수 ㅇ벗다.
- 변수의 final은 변경하지 못한다는 거다
- enum
- final로 String과 같은 문자열이나 숫자들을 나타내는 기본 자료형의 값을 고정할 수 있음. (상수 = constant)
- enumeration 이라는 셈 계산 열거 목록 일람표에서 따옴
- 클래스의 일종이다.
- 문자열에 비해 IDE의 지원(자동완성, 오타검증, 텍스트 리팩토링)
- 허용가능한 값들을 제한할 수 있음.
- 리팩토링시 변경 범위의 최소화
- 생성자가 자동으로 생성됨.
- 부모 클래스는 무조건 java.lang.Enum이어야 한다.
- protected Enum(String name, int ordinal) 컴파일러 레벨에서만 호출
- Enum 클래스 개발자들이 clone, finalize, hashCode, equals를 오버라이드 하지 못하게 막았음.
- compareTo : Enum이 선언된 순서대로 각 상수들의 순서가 정해진다. 이 함수는 순서가 다른지 같은지를 비교한다.
- API 문서에 없는 values 라는 특수한 메소드가 있음. 모든 상수를 배열로 리턴함.
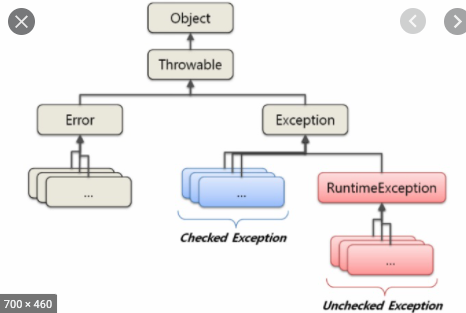
- try-catch
- 모든 예외의 부모 클래스는 java.lang.Exception 클래스
- Exception 클래스는 java.lang 패키지에 선언되어 있어서 별도로 import 할 필요 없음.
- intArray = null; intArray[5] 이런 경우면, null인지 부터 먼저 확인하기 때문에 NPE가 먼저 발생한다. NPE가 발생하면 모든 내용을 무시하기 때문에 AIOBE는 발생하지 않는다.
- try 다음에 오는 catch 블록은 1개 이상 올 수 있다.
- 먼저 선언한 catch 블록의 예외 클래스가 다음에 선언한 catch 블록의 부모에 속하면 자식에 속하는 catch블록은 절대 실행되지 않기 때문에 컴파일 되지 않는다.
- 하나의 try 블록에서 예외가 발생하면 그 예외와 관련이 있는 catch 블록을 찾아서 실행한다.
- catch 블록중 발생한 예외와 관련있는 블록이 없으면, 예외가 발생하면서 해당 스레드는 끝난다.
- 예외의 종류
- checked exception :아래의 예외를 제외한 모든 예외들. 바로 Exception 클래스를 활장.
- error : 자바 프로그램 밖에서 발생한 예외. 서버의 디스크가 고장나거나, 메인보드가 고장났을 때.
- runtime exception : 런타임 예외. NPE는 컴파일타임에서 발생하지 않는다. (+ NumberFormatException, ClassCastExcpetion, ArrayOutOfBoundsException...)
- unchecked exception
- 자바7 부터는 or를 나타내는 파이프를 연결하여 여러개의 예외를 한 블럭으로 해결 가능
- java.lang.Throwable 모든 예외의 부모 클래스
- Exception과 Error의 부모 클래스는 Object 이지만 Throwable이라는 공통부모 클래스가 또 존재한다.
- Exception, Error를 처리할 때 Throwable로 처리해도 무관.
- 종류
- Throwable() : 기본 생성자.
- Throwable(String message) : 예외메세지를 String으로 넘겨줄 수 있다.
- Throwable (String mesage, Throwable cause)
- Throwable(Throwable cause)
- Thorwable에 선언된 주요 메소드
- getMessage : 예외 메세지를 String으로 제공받는다.
- 어떤 예외가 발생했는지 확인할 때 유용함.
- toString() : 예외 메세지를 String 으로 제공받는다. 위보다 더 자세하게 예외 클래스 이름도 같이 제공받음
- printStackTrace() : 가장 첫줄에는 예외 메세지를 출력하고, 두 번째 줄부터는 예외가 발생하게 된 메소드들이 호출관계를 출력해준다.
- getMessage : 예외 메세지를 String으로 제공받는다.
- throw를 통해 의도적으로 예외발생시킬 수 있다.
- 함수를 public void -- throws Exception 이렇게 선언하면 Try-catch로 묶지 않아도 그 메소드를 호출한 메소드로 예외처리를 위임하여 문제가 되지 않는다.
- throws : 메소드 선언시 해당 예약어를 사용하면, 메소드에서 선언한 예외가 발생해씅ㄹ 때 호출한 메소드로 예외가 전달된다. 만약 메소드에서 두 가지 이상의 예외를 던질 수 있다면 implements 처럼 콤마로 구분하여 예외 클래스 이름을 적어주면 된다.
- public void function() throws NPE, Exception 이렇게 선언하면 된다.
- try 블록 내에서 예외를 발생시킬 경우에는 throws라는 예약어를 적어 준 뒤 예외 객체를 생성하거나 생성되어 있는 객체를 명시해준다.
- throw한 예외 클래스가 catch 블록에 선언되어 있지 않거나, throws 선언에 포함되어 있지 않으면 컴파일 에러가 발생함.
- catch 블록에서 예외를 throw할 경우에도 메소드 선언의 throws 구문에 해당 예외가 정의되어 있어야만 한다.
- 예외를 throw하는 이유는 해당 메소드에서 예외를 처리하지 못하는상황이거나, 미처 처리하지 못한 예외가 있을 경우에 대비하기 위함.
- public class MyException extends Exception 이렇게 예외 클래스를 만들 수 있다 . Throwable이나, 그 자식 클래스를 상속받아야만 만들 수 있다.
- throw : 예외 객체를 던질 때
- thorws : 예외가 발생하면 던질것이라고 메소드 선언시 사용
- 자바 예외처리 전략 :
- RuntimeException으로 확장하여 선언하면 해당 예외를 throw하는 메소드는 try-catch로 묶지 않아도 컴파일 시에 예외가 발생하지 않는다.
- 하지만 이 클래스를 호출하는 다른 클래스에서 예외를 처리하도록 구조적인 안정 장치가 되어 있어야 한다.
- unchecked exception인 RuntimeException이 발생하는 메소드가 있다면, try-catch로 묶지 않아도 컴파일 타임에 문제가 되지 않지만, 런타임에서 문제가 될 수 있어서 try-catch로 묶어주는것이 좋다.
- 임의의 예외 클래스를 만들 때에는 반드시 try-catch로 묶어줄 필요가 있을 경우에만 Exception으로 확장하고, 일반적으로는 RuntimeException을 확장하는 것을 권장
- catch문 내에 아무런 작업 없이 공백을 놔두면 예외 분석이 어려워지므로 꼭 로그 처리와 같은 예외 처리를 해줘야만 한다.
- finally : 예외 발생 여부와 상관없이 실행된다. 코드 중복을 피하기 위해서 반드시 필요함.
- String
- public final class String extends Object implements Serializable, Comparable<String>, CharSequence
- final 클래스라 확장 불가능
- Serializeable은 구현해야할 메소드가 하나도 없는 특이한 인터페이스. implement하게 되면 객체를 파일로 저장하거나 다른 서버에 전송 가능한 상태가 된다. (직렬화가 가능해진다)
- Comparable은 compareTo 메소드 하나만 선언되어 있음. 이 메소드는 매개변수로 넘어가는 객체와 현재 객체가 같은지를 비교하는데 사용한다. equals()와 동일해 보이지만, 리턴타입이 int이다. 같으면 0이지만 순서상 앞에 있으면 -1, 뒤에 있으면 1을 리턴함. 객체의 순서를 처리할 때 유용.
- CharSequence : 해당 클래스가 문자열을 다루기 위한 클래스라는 것을 명시적으로 나타내는 데 사용함.
- 생성자
- byte 배열을 넘겨받거나, 캐릭터셋을 사용하여 디코딩 하거나, STringBuffer, StringBuider를 통해 객체를 생성할 ㅅ ㅜ있음.
- Byte로 변환
- getBytes()나, 캐릭터 셋을 넘겨서 바이트 배열을 만들 수 있다.
- java.nio.Charset 클래스는 표준 캐릭터 셋이 정해져 있음.
- 한글은 byte 배열로 만들 때 어떤 캐릭터 셋을 쓰느냐에 따라 배열의 크기가 다름
- convert는 try-catch로 감싸야 한다. UnsupportedEncodingException을 발생시킬 수 있음. 존재하지 않는 캐릭터 셋의 이름을 지정할 경우 이 예외 발생함.
- 문자열 비교
- eqauls()
- String 클래스는 ==을 통해서도 비교가 가능하다. 왜냐하면 Constant Pool에 저장되기 때문.
- Constant Pool은 String의 경우 동일한 값을 갖는 객체가 있으면, 이미 만든 객체를 재사용 한다.
- 하지만 new String(""); 이렇게 생성하면 Constant Pool의 값을 재활용 하지 않고 별도의 객체를 생성한다.
- compareTo
- 순서까지 비교해줌, int로 리턴 오름차순이면 양수, 내림차순이면 음수.
- contentEqauls
- eqauls()
- 특정 조건에 맞는 문자열이 있는지를 확인하는 메소드(모두 boolean타입
- startWith : 매개변수로 시작하는지 확인함. indexOf로도 할 수 있지만 모든 문자열의 내용을 확인해봐야하는 단점이 있음
- endsWith : 매개변수로 끝나는지 확인함
- contains : 단순히 문자열이 포함되어있는지 확인
- matches : 위와 유사하지만, 정규표현식으로 되어 있어야 함 java.util.regex의 Pattern 확인
- regionMathces : 특정 영역이 일치하는지 확인하는 메소드.
- 위치 알아내기
- indexOf : 왼쪽부터 문자열이나 char를 찾는다
- lastIndexOf : 뒤쪽부터 문자열인
- 일부만 추출하기
- charAt(int index) : 특정 위치의 캐릭터값
- getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) : 매개변수로 넘어온 char 배열내에 있는 char를 저장함.
- int codePointar : 특정 위치의 유니코드 값 리턴
- int codePointBefore : 특정 위치 앞에 있는 char의 유니코드 값을 리턴
- int corePointCount : 지정한 범위에 있는 유니코드 갯수 리턴
- int offsetByCodePoints : 지정된 index부터 오프셋이 설정 인덱스를 리턴
- char 배열의 값을 String으로 변환
- copyValueOf() : char 배열에 있는 값을 문자열로 변환. null이면 "null"이라는 문자열을 리턴해줘서 안전하다.
- copyValueOf : char 배열에 있는 값을 문자열로 변환. 단 offset위치부터 count가지 갯수만큼 문자열로 변환함.
- String의 값을 char 배열로 변환하는 메소드
- toCharArray : 어떤 String 객체를 만들어도 그 객체는 내부에 char 배열을 포함한다.
- 문자열의 일부 값을 잘라내는 메소드
- substring :String으로 리턴
- subSequence : CharSequence 타입으로 리턴
- 문자열을 여러개의 String 배열로 나누는 split
- split : regex에 있는 정규표현식잘라 String 배열로 리턴함. 특정 알파벳이나 기호 하나로 문자열을 나누려고 할 때 편함.
- StringTokenizer : 특정 String으로 문자열을 나누려고 할 때 편함.
- String값을 바꾸는 메소드
- concat : 매개변수로 받은 str를 기존 문자열릐 우측에 붙인 새로운 문자열 객체를 생성하여 리턴함 (합치기)
- trim : 문자열 맨 앞과 뒤의 공백을 제거한 문자열 객체를 리턴함.
- 공백만으로 이뤄진 값인지, 공백을 제외한 값이 있는지 확인할 때 편함
- 내용을 교체하는 메소드
- replace : 해당 문자열의 oldCahr를 newChar로 변경. target과 같은 값을 replacement로 대체
- replaceAll : 해당 문자열 내용중 regrex에 포함된 정규 표현식은 모두를 replacement로 변경
- replaceFirst : regrex해 해당하는 부분중 첫번째 내용만 replacement로 변경.
- 특정 형식에 맞춰 값을 치환하는 메소드
- static String format : format에 있는 문자열의 내용중 변환해야 하는 부분을 args의 내용으로 변경
- %s, %d, %f 등
- format : foramt에 있는 문자열의 내용 중 변환해야 하는 부분을 args의 내용으로 변경한다. 단 첫 매개변수인 Locale 타입의 1에 선언된 지역에 맞추어 출력한다.
- static String format : format에 있는 문자열의 내용중 변환해야 하는 부분을 args의 내용으로 변경
- 대소문자를 바꾸는 메소드
- toLowerCase : 소문자, 매개변수로 지역 정보를 넣을 수 있음
- toUpperCase : 대문자
- 기본 자료형을 문자열로 변환하는 메소드
- valueOf(기본 자료형) 혹은 + ""를 통해 변경해도 된다.
- null인 객체는 toString() 대신에 valueOf를 쓰는게 좋다. toString은 NPE를 던진다. 하지만 valueOf()는 "null"문자열을 던짐
- 절대 사용하면 안되는메소드
- intern() -> C로 구현되어 있는 native 메소드. 심각한 성능 저하 발생 가능.
- new String()으로 생성할지라도, 풀에 해당값이 있으면 풀에 값을 참조하는 객체를 리턴한다.
- 그래서 intern를 호출하면 == 를 사용할 수 있다.
- 성능상 ==으로 비교하는 것이 훨씬 빠르다. 하지만 intern을 통해 억지로 문자열 풀에 할당하면 저장되는 영역에 한계가 있어 메모리를 청소하게 되어, 작은 연산 하나를 바르게 하기 위해 전체 자바 시스템에 성능에 악영향을 준다.
- 애플리케이션에서 생성하는 문자열이 정해져 있고, 그 문자열에 대해서만 intern() 메소드를 호출하여 사용할 경우에는 문제가 되지 않을 수 있지만 완전히 정해져 있는 시스템은 거의 없어 intern()를 사용하면 안된다;
- intern() -> C로 구현되어 있는 native 메소드. 심각한 성능 저하 발생 가능.
- public final class String extends Object implements Serializable, Comparable<String>, CharSequence
- StringBuffer
- immutable(불변한)한 String의 단점을 보완하는 클래스
- String text = "Hello"; text = text + " world"; 이렇게 하면 "Hello"라는 단어를 갖고 있는 객체는 더이상 사용 불가능 하다. 이 단점을 보완하기 위해 탄생했다.
- 스레드 세이프하다.
- 문자열을 더하더라도 새로운 객체를 생성하지 않는다.
- append()를 통해 기본 자료형과 참조 자료형을 모두 포함한다
- append()를 실행한 후에도 StringBuffer를 호출하기 때문에 연달아 append()를 실행 할 수 있다 .
- CharSequence 인터페이스를 구현함. String, StringBuilder 타입보다는 CharSequence 타입 으로 받는 것이 좋다.
- 어떤 클래스에 문자열을 생성하기 위한 문자열을 처리하기 위한 인스턴스 변수가 선언되고, 여러 스레드가 변수에 동시 접근할 일이 있으면 StringBuffer를 사용해야만 한다.
- StringBuilder
- CharSequence 인터페이스를 구현함.
- NestedClass
- 클래스 안에 클래스가 들어갈 수 있다. 코드 간결하게 하기 위해서. 혹은 사용자 입력, 외부의 이벤트에 대해 처리를 하는 곳에서 많이 쓰임.
- 목적 :
- 한 곳에서만 사용되는 클래스를 논리적으로 묶어서 처리할 필요가 있을 때 (Static nested class)
- 캡슐화가 필요할 대 즉 내부 구현을 감추고 싶을 때(inner class)
- 소스의 가독성과 유지보수성을 높이고 싶을 때.
- Static nested class
- 내부 클래스는 감싸고 있는 외부 클래스의 어떤 변수도 접근할 수 있다. private도 접근 가능함. 하지만 Static nsted 클래스를 그렇게 사용하는 것은 불가능. 말 그대로 Static 하기 때문이다.
- Nested 클래스는 별도로 컴파일 할 필요가 없다. 왜냐하면 감싸고 있는 클래스를 컴파일 하면 자동으로 컴파일 되기 때문이다.
- StaticNested 클래스가 static으로 선언되어 있어 부모 클래스에서 static 변수만 참조할 수 있다.
- 하지만 감사고 있는 클래스에서는 Static NEsted 클래스 의 인스턴스 변수나 내부 클래스의 인스턴스 변수로의 접근이 가능하다.
- 외부 클래스를 만들지 않아도 인스턴스화 할 수 있다.
- inner(내부) class(Static을 붙이지 않았을 뿐)객체를 생성한 다음에 사용하는방법에서 차이가 있다.
- 하나의 클래스에서 어떤 공통적인 작업을 수행하는 클래스가 필요한데 다른 클래스에서 전혀 필요 없는 ㄱ경우 내부 클래스를 만들어 사용한다.
- Loacl Inner class
- Annoymous inner class (내부 클래스를 만드는 것보다 더 간단한 방법)
- 클래스 이름도 없고 객체 이름도 없어. 다른 클래스나 메소드에서는 참조할 수 없다.
- 클래스를 만들고 그 클래스를 호출하면 그 정보는 메모리에 올라가기 때문에 메모리가 많이 필요해지고, 애플리케이션을 시작할 대 더 많은 시간이 소요된다. 따라서 자바에서는 간단한 방법을 통해 객체를 생성할 수 있도록 해놓은 것이다.
- 바깥 클래스부터 객체 생성을 하고 내부 클래스를 인스턴스화 할 수 있다.
- Listner lister = new Lister () {
- public void onClick() { 이런식으로 클래스 내부에서 재사용 할 수 있게 변수로 선언할 수 있다.
- 혹은 button.setListenr(new Listenr() {
- public void onClick ... ) 이런식으로 바로 바로 setListenr로 생성자를 호출해서 바로 넘겨줄 수도 있다.
- 어노테이션
- 메타데이터, 1.5 부터 등장
- 역할
- 컴파일러에게 정보를 알려주거나
- 설치시 작업을 지정
- 실행할 때 별도의 처리가 필요할 때
- 미리 정해진 어노테이션(딱 3개뿐)
- @Override :
- @Depreaceted : 더이상 사용되지 않는 경우. 하휘호환성을 위해서 선언하는 것이 필요하다.
- @SupreeWarnings : 경고를 무시하라는 의미
- 어노테이션을 선언하기 위한 메타 어노테이션
- @Target : 어떤 것에 적욜할지. 생성자에 할지, 메소드에 할지 등등
- CONSTURCTOR
- FILED
- LOCAL_VALARIABLE
- METHOD
- PACKAGE
- PARAMETER
- TYPE
- @Retention : 얼마나 오래 어노테이션 정보가 유지(생명주기의 범위)되는지. 컴파일시 사라질 지, 실행시에만 참조 가능한지, 가상머신에서 살아질지
- SOURCE : 어노테이션 정보가 컴파일시 사라짐
- CLASS : 클래스 파ㅣㅇㄹ에 있는 어노테이션 정보가 컴파일러에 의해서 참조 가능함. 하지만 VM에서는 사라짐 (런타임때 사라짐)9
- RUNTIME : 실행시 어노테이션 정보가 VM에 의해 참조 가능(런타임떄)
- @Documented : 어노테이션 정보가 Javadocs 문서에 포함된다는 것을 선언
- @Interited : 부모 클래스의 오너테이션을 사용 가능하다는 것을 의미.
- @interface : 어노테이션을 선언할 때 사용.
- @Target : 어떤 것에 적욜할지. 생성자에 할지, 메소드에 할지 등등
- 어노테이션 상속
- enum도 상속되지 않듯이, 미리 만들어 놓은 어노테이션을 확장하는 것이 불가능하다. 즉 extends라는 예약어 사용 불가ㅡㄴㅇ하다.
- 어노테이션의 목적
- 제약사항등 선언 @Deprecated, @Override, @Nonnull
- 용도를 확인하기 위해 @Entity, @TestCase, @WebService
- 행위를 나타내기 위해 ,@Statefull, @Transaciton
- 처리를 나타내기 위해 @Column, @XmlElement8
- 비트연산자
- java.lang.Math
- 자바의 역사
- 1991년 Green이라는 프로젝트로 시작. 제임스 고슬링 참여. TV와 시청자 상호작용 할 수 있는 것을 만들기 위해서 시작됨.
- 1992년 Oak라는 언어, 1995년 Java로 바뀜. WORA모토 생김.
- 자바의 버전별 차이
- 자바의 특징
- 견고하고 보안상 안전
- 아키텍쳐에 중립적이고 포터블함
- 높은 성능
- 인터프리터 언어, 스레드 제공,동적인 언어
- 자바의 버전별 차이
- JDK 1.0 최초의 버전
- JDK 1,1 내부 클래스 기능 추가, JavaBeans(자바 컴포넌트 모델), JDBC, RMI(Remote JVM에 있는 메소드 호출가능) 추가
- JDK 1.2 (J2SE) stirctfp 예약어 추가 , JIT가 SUN JVM에 추가, Collection 추가
- JDK 1.3 HotSpot JVM 추가, JNDI 추가,
- JDK 1.4 assert 추가, 정규표현식 추가, exception chnaing 추가(예외 캡슐화 가능), NIO추가, Preference API 추가
- Java 5 제너릭 추가, 어노테이션 추가, enum 추가, varagrs추가, concurrent추가
- Java 6
- Java 7
- Java 8
- float, double의 범위
- 비트연산
- Java.lang.Math
- 얕은복사 : 참조값만 복사
- 깊은 복사 : 값 자체를 완전히 복사에서 독립적인 공간을 만듦.
- JIT 컴파일러
- Just In Time의 약자. 자바와 .NET에서 사용.
- 동적 변환이라고도 하고, 프로그램 실행을 보다 빠르게 하기 위해 실행시 적용되는 기술
- 인터프리터 방식과 정적 컴파일의 혼합. 변환 작업은 지속적으로 인터프리터에 의해 수행되지만, 필요한 코드의 정보는 캐시에 담아두었다가 재사용함.
- 인터프리터 방식
- 프로그램을 실행할 때 마다 컴파일
- 정적 컴파일 : 컴파일을 미리 한번만 실행함.
- Hotspot VM (더 찾아봐야함)
- 클라이언트, 서버 컴파일러 두가지를 다 제공한다. CPU코어가 하나인 사용자를 위해 만들어진 것이 Hotspot 클라이언트 컴파일러.
- 특징 : 애플리케이션 시작을 빠르게 하고, 적은 메모리를 점유하도록 하는 것.
- 코어가 많은 장비에서 애플리케이션을 돌리기 위해 만들어진 것이 hotspot 서버 컴파일러.
- JVM : 자바 프로그램이 수행되는 프로세스
- JDK
- GC
- Full GC
- Serial GC는 JVM에서 사용하면 안된다.
- static void gc()
- static void runFinalization() :GC를 기다리는 모든 객체에 대해 finalize()
- Full GC
- lang클래스 : 유일하게 import 하지 않아도 사용할 수 있는 클래스
- 최상위 클래스인 Object 포함, 기본형 타입을 객체로 변환시키는 Wrapper 클래스 포함. 문자열과 관련된 String, StringBuffer, StringBuilder 포함, System, Math, Thread, 등등 포함 오토박싱, 오토언방식 지원
- 분류
- 언어관련 기본
- 문자열 관련 String, StringBuffer , StringBuilder
- 기본자료형 및 숫자 관련
- 스레드 관련
- 예외 관련
- 런타임 관련
- 인터페이스
- 클래스 String, StringBuffer, StringBuilder
- 예외 Throwable, Exception
- 문자열 관련 CharSequence
- 기본 자료형 및 숫자(더 찾아보기
- 숫자:기본 자료형은 힙에 저장되지 않고 스택에 저장된다.따라서 계산할 때 빠른 처리가 가능함
- 모두 Number라는 추상 클래스를 확장한다.Wrapper클래스라고 불린다.
- parese,valueOf라는공통 메소드를 제공한다.(문자열을 분석하여 해당 타입으로 변경 해주는 메소드)parse는Primitive타입을 전달해주고 (Int).valueOf는 Wrapper클래스 타입 (new Interger())으로 전달해줌.(객체를 전달해준다)
- parse : Number.pare~ -> 문자열을 파싱하여 문자열에 포함된 숫자 부분을 숫자형으로 반환함.
- valueOf() : Number인스턴스가 가지고 있는 값을 반환함.
- Byte
- Short
- Integer
- Long
- Float
- Double
- Character
- Boolean
- 스레드 관련 Runnable, Threasd, ThreadGroup, ThtreadLocla, Thread.State
- 런타임 관련
- 어노테이션 : 소스코드 상에서 메타데이터를 표현하기 위한 방법
- @Override : 오버라이드 되어 있는지 검증
- @Deprecate : 메소드를 사용하지 않도록 유도
- @SupressedWarining : 컴파일 경고를 무시
- System 클래스 : 각종 정보를 확인하기 위한 System 클래스
- 시스템 속성값 관리 : Property 클래스 : java.util 클래스에 속하고 Hashtable의 상속을 받은 클래스. (자바 버전 등), 추가 수정이 가능함
- 시스템 환경값 조회.읽기만 가능하다.
- getenv() :환경값에 대한 Map 형태로 리턴받음
- JAVA_HOME. JDK 설치 경로 확인 가능
- GC수행
- gc() : 실행
- runFinalization : GC 처리를 기다리는 모든 객체에 대해서 finalize()를 실행함
- JVM 종료 : 절대 실행 하면 안됨. JVM이 죽어버림.
- 현재시간 조회
- curretnTimeMillis 현재 시간을 밀리초 단위로 출력. 주로 현재 시간을 확인하기 위한 메소드.
- currentTime() 현재 시간을 나노초 단위로 리턴
- System.out
- 객체를 출력할 때 toString() 보다 valueOf() 메소드를 실행하는게 안전함.
- System 클래스에 선언되어 있는 out, err 변수는 PrintStream이라는 동일한 클래스의 객체임. 에러가 났을 때 ㅎ출력 결과인지 차이만 존재함.
- 그외
- 시스템환경값 조회
- Static Map<String, String> getenv() 현재 시스템 환경에 대한값 리턴
- static String getenv(String name) 지정한 name에 해당하는 값음 받음
- 시스템환경값 조회
- 제너릭
- Java5에 새로 추가됨
- 타입 형변환에서 발생할 수 있는 문제를 사전에 없애기 위해 만들어짐
- 제네릭은 클래스 내부에서 사용할 데이터 타입을 외부에서 지정하는 기법
- 타입 형 변환에서 발생할 수 있는 문제점을 사전에 없애기 위해 컴파일시 타입 체크를 해주는 기능
- E 요소 Element
- K 키 Key
- N 숫자 Number
- T 타입 Type
- V 값 Value
- R Result
- 사용하지 않았을 때 발생할 수 있는 문제점
- Int형 배열에 String을 넣으면 캐스팅 에러 뜸. 컴파일 시에는 발생하지 않는 에러
- 제너릭을 사용하여 문제해결
- 제너릭을 사용하여 컴파일러가 알아서 형변환을 진행함.
- 한정적 타입 매개변수
- 제네릭으로 사용할 타입 파라미터의 범위를 제한할 수 있는 방법
- 특정 클래스의 서브 클래스 타입으로만 제한하고 싶은 경우
- <T extends Number> -> Number의 하위 클래스만 담길 수 있도록 함
- 특정 클래스의 상위 클래스 타입으로만 제한하고 싶은 경우
- <T super Numebr> -> Number의 상위 클래스만 담실 수 있도록 함.
- 제너릭을 사용할 수 없는 경우
- 제너릭 메서드
- 매개변수 타입과 리턴 타입으로 타입 파라미터를 갖는 메소드
- wildcard로 메ㅐ소드를 선언하는 방법에는 단점이 존재 : 매개변수로 사용된 객체에 값을 추가할 수 없다.
- 제너릭 메소드를 호출하는 두가지 방법
- Box<Integer> box = <Integer>boxing(100); 타입 파라미터를 명시적으로 Integer로 지정
- Box<Integer> box = boxing(100); // 타입 파라미터를 Integer로 추정
- public <T extends Car> void boundedGenericMethod(WildcardGeneric<T> c, T addValue)
- public <S, T extends Car>
- 와일드 카드
- 파일을 지정할 때 구체적인 이름 대신에 여러 파일을 동시에 지정할 목적으로 사용하는 특수기호
- 어떤 타입이 제너릭이 될 지 모를때 사용
- 매개변수에서만 사용, 함수 리턴 타입에는 불가능
- 세가지 타입 존재
- 제너릭 타입 <?> 모든 클래스나 인터페이스 타입이 올 수 있음.
- <? extends 상위T> : 상위 T의 하위 클래스만 올 수 있음.
- <? super 하위T> : 하위 T의 상위 클래스만 올 수 있음
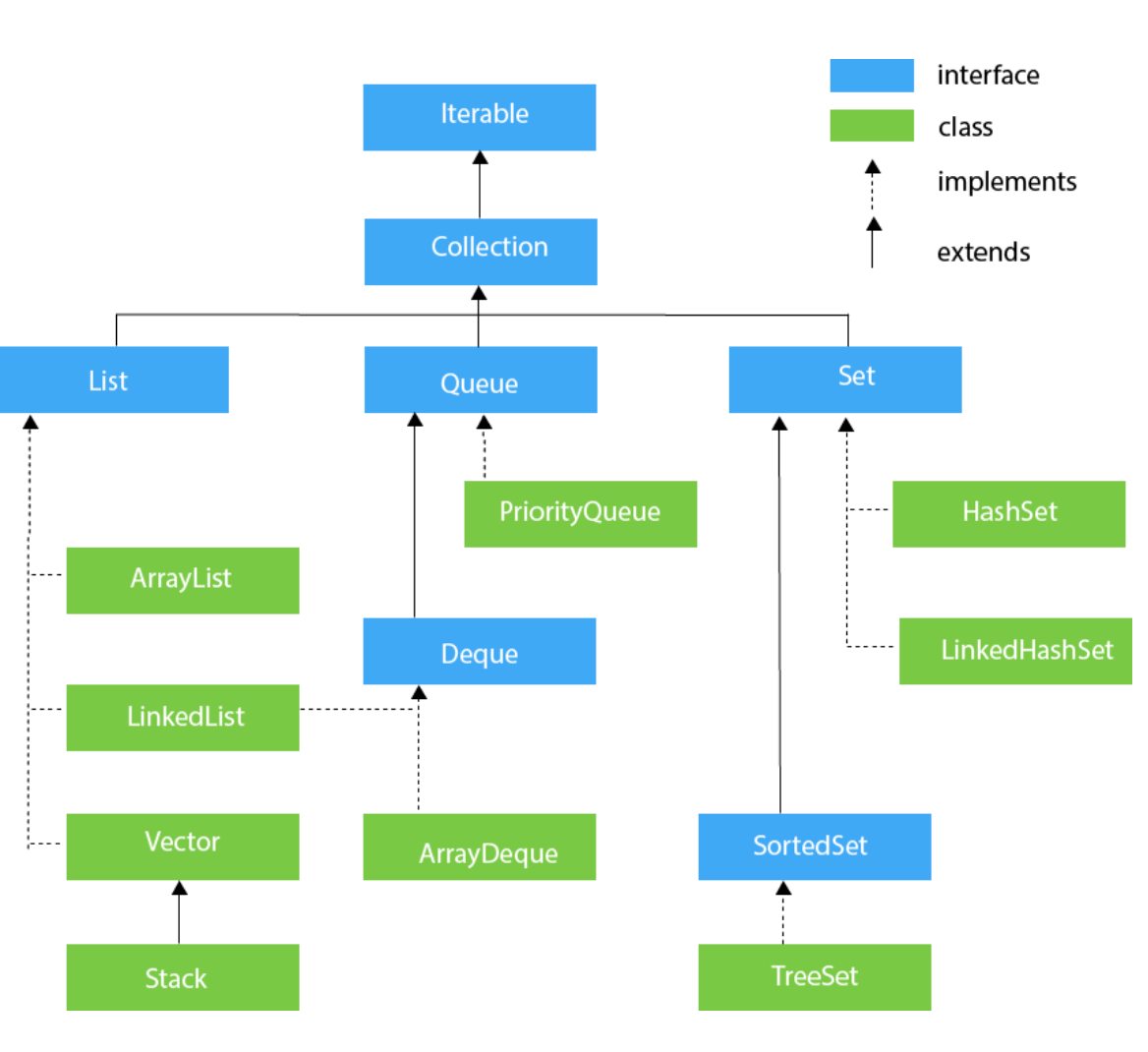
- 자바 컬렉션
- 여러 원소들을 담을 수 있는 자료구조. java.util에 선언됨.
- Collection 인터페이스
- List,Set 인터페이스의 많은 공통된 부분을 Collction 인터페이스에서 정의하고, 두 인터페이스는 그것을 상속받음.
- public interface Collection<E> extends Iterable<E>라고 선언되어 있음. 데이터를 순차적으로 가져올 수 있다는 것을 의미함.
- Iterator라는 메서드를 통해 hasNext(), 현재 위치를 남기고 리턴해주는 next(), 삭제 remove()가 있음
- 대표적으로 List, Set, Queue
- List 인터페이스
- 순서가 있음. 객체를 인덱스로 관리하여 객체를 추가하면 자동으로인덱스가 부여.
- List 컬렉션은 객체 자체를 젖아하는 것이 아니라 객체의 참조를 저장한다.
- add, addAll, contain, containsAll, equals, get, size,remove, removeAll, size, clear, isEmpty, iterator, rtoArray기능의 메서드가 선언됨.
- java.util 패키지에서는 ArrayList, Vector,Stack LinkedList를 많이 사용함.
- 종류
- ArrayList :
- 스레드 세이프하지 않음.
- 내부에는 처음 설정한 저장 용량이 있음. 설정한 용량크기를 넘어서 다른 객체가 들어오면 자동적으로 저장 용량이 늘어난다.
- 확장 가능한 배열. JDK 1.2부터 생김
- 특정 인덱스를 제거하면 객체의 인덱스부터 마지막 인덱스까지 모두 앞으로 1칸씩 이동.인덱스 값을 유지하기 우해서 전체 객체가 위치가 이동함
- 객체 삭제와 삽입이 빈번하게 일어나는 곳에서 사용하지 않는 것이 좋음. 그 대신 LinkedList를 사용하는게 좋음
- 검색, 맨 마지막 인덱스에 객체 추가에 좋은 성능 발휘
- 상속 구조
- Object > AbstractCollection <E> > AbstractList<E> > ArrayList<E> 상속 구조
- 구현한 인터페이스들
- Serializable (원격으로 객체를 전송하거나, 파일에 저장할 수 있음을 지정),
- Cloneable(Object클래스의 clone이 수행이 가능함을 지정, 복제가 가능한 객체임을 의미).
- Interable<E> (forEach 문장을 사용할 수 있음을 지정),
- Collection<E> (여러개의 객체를 하나의 객체에 담아 처리할 때의 메소드 지정), List<E> (목록형 데이터를 처리하는 것과 관련된 메소드 지정), (
- RandomAccess(목록형 데이터보다 빠르게 접근할 수 있도록 임의로 접근하는 알고리즘이 적용된다는 것을 지정)의 인터페이스를 구현함
- 기본적으로 객체 저장 공간을 10개를만듬
- 매개변수로 컬렉션 객체를 넘기거나 초기의 저장공간을 지정 가능함.
- lentgh는 저장공간의 크기. size는 데이터의 갯수
- LinkedList : 리스트에도 속하면서 큐에도 속함
- 객체 삽입 및 삭제에 좋은 성능을 발휘함
- Vector
- 스레드 세이프함
- 1.0 부터 있었음
- ArrayList와 동일한 내부 구조를 가지고 있음.
- 생성할 때 저장할 원소의 타입을 지정해야함.
- 스레드 세이프 하지만 속도를 포기한 트레이드 오프가 존재
- Stack :
- Vector 클래스 확장 하여 만듬 (스레드 세이프함)
- LIFO 가장 마지막에 들어온 것을 가장 처음에 빼냄
- 상속 구조 java.lang.Object > java.util.AbstractCollection<E> > java.util.AbstractList <E> > java.util.Vector<E> java.util.Stack<E>
- LIFO를 지원하기 위해서 만듦 (후입선출)
- 스레드 세이프 함
- 성능이 더 좋은 ArrayDeque가 존재함 (스레드 세이프 하지 않음)
- 확장한 인터페이스는 ArrayList와 모두 동일하다.
- Stack 클래스는 자바에서 상속을 잘못 받은 케이스. 1.0부터 존재해왓서 하휘호환성을 위해 이 상속 관계를 유지하고 있는 거다
- peek() : 객체의 가장 위에 있는 데이터를 리턴함, pop()은 가장 위에 있는 데이터를 지우고 리턴한다.
- ArrayDeque
- 스레드세이프 하지 않음.
- LIFO
- ArrayList :
- Set 인터페이스
- 순서에 상관없이 어떤 데이터가 존재하는지를 확인하기 위한 용도로 사용됨. 중복을 방지하고. 원하는 값이 포함되어 이는지 확인하는 것이 주 용도.
- 배열로 이 행위를 하려면 indexOf()로 존재 여부를 확인하면서 add()로 추가하는 작업을 반복해야됨.
- 주요 클래스
- HashSet : 순서가 전혀 필요없는 데이터를 HashTable에 저장함. 성능이 가장 좋음 스레드 세이프 하지 않음. 정렬 작업이 없어 제일 빠름.
- java.lang.Object > java.util.AbstractColletion<E> > java.util.AbstractSet<E> ? java.util.HashSet 상속구조를 띈다.
- AbstractSet에는 equals(), hashCode(O) ,. removeAll 만 존재한다.
- 확장한 인터페이스 : Serializeable 원격으로 객체 전송 , Cloneable 복제 가능한 객체. Iterable foreach 상 용 가능, Collection 여러 객체를 하나의 객체에 보관 가능, Set 셋 데이터 처리 관련
- TreeSet : 저장된 데이터 값에 따라 정렬 되는 셋임. 레드 블랙 트리로 저장되고, HashSet보다 성능이 약간 느림
- LinkedHashSet : 연결된 목록 타입으로 구현된 해시 테이블에 데이터를 저장함. 저장된 순서에 따라 값이 정렬됨. 성능이 가장 나쁨.
- HashSet : 순서가 전혀 필요없는 데이터를 HashTable에 저장함. 성능이 가장 좋음 스레드 세이프 하지 않음. 정렬 작업이 없어 제일 빠름.
- Map 인터페이스
- Key, value 형태로 데이터를 저장
- put 저장, get 읽기, remove 지우기
- 주요 클래스
- HashMap
- 키나 값에 null 저장 가능. (Hashtable은 불가능) 스레드 세이프 하지 않음.
- 상속 구조 Object > AbstractMap > HashMap 구조
- Serilzable, Cloneable, Map을 구현하고 있음
- 16개의 기본 저장 공간을 갖음. 생성자에서 저장공간을 변경할 수 있고, 로드팩터도 지정가능함.
- 초기에 데이터의 갯수가 많은 경우에 초기 크기를 지정해주는 것을 권장
- 키값은 기본형, 참조형 모두 가능함. 참조형일 때는 hashCode , equals를 잘 구현 해야 한다.
- hashCode 메소드의 결과 값에 따른 버킷(목록 형태의 바구니가 만들어짐) 생성
- 버킷에 들어간 목록에 데이터가 여러개이면 equals 메소드를 호출하여 동일한 값을 찾게 된다. 따라서 hashcode, equals를 참조형 전용으로 잘 구현해야 한다
- Collections 에서는 ArrayIndexOutOfBoundsException이라는 예외가 있지만, Map에서는 null 값을 리턴함
- Set에서는 데이터가 중복되지 않는 것이 중요하고, Map 에서는 키 값이 중복되지 않는 것이 중요하다.
- 주요 메소드
- values 라는 메소드를 사용하면 HashMap에 담겨있는 값의 목록을 Collection 타입의 목록으로 리턴해줌.
- TreeMap
- 이진 트리의 형태로 버킷을 저장
- SortedMap 인터페이스를 구현.
- 키가 정렬이 되었을 때 장점은 가장 앞에 있는 키, 가장 뒤에 있는 키 특정 키 뒤 에있는 키, 특정 키 ㄱ앞에 있는 키 등을 알 수 있다
- HashMap보다는 추가 삭제 성능이 떨어진다. 데이터를 저장할 때 즉시 정렬하기때문에.
- 정렬된 상태로 Map을 츄지해야 하거나 정렬된 데이터를 조회해야 하는 범위 검색이 필요한 경우 유리함.
- Properties 클래스
- Hashtable을 확장함. Map 인터페이스에서 제공하는 모든 메소드를 사용할 수 있음.
- LinkedHashMap
- Queue 인터페이스
- 선입선출 FIFO
- 시간순으로 어떤 작업 또는 데이터를 처리할 필요가 있을 때 사용
- BFS 너비 우선 탐색에 사용됨
- 주요메소드
- Boolean offer(E e) 큐의 마지막에 요소를 추가함.
- E poll() 큐의 첫번째 요소르 제거하고 제거된 요소를 반환함
- E peek() 큐의 첫번째 요소를 제거하지 않고 반환함.
- LinkedList
- 배열보다 메모리 공간 측면에서 훨씬 유리함
- 배열의 중간에 있는 데이터가 지속적으로 삭제되고 추가될 경우
- Queue와 Deque 인터페이스도 구현하고 있다. (리스트이면서 큐)
- 상속 구조 Objeect> AbstractCollection > AbstrctList > AbstrctSequentailList > LinkedList
- Deque 인터페이스를 확장함. 맨앞과 맨 뒤 값을 용이하게 처리하는 큐와 관련된 메소드를 지정
- 처음의 크기를 지정하지 않음 데이터들이 앞뒤로 연결되는 구조여서 미리 공간을 만들어 놓을 필요가 없다
- 이전 데이터도 검색할 수 있는 desendingIterator()도 지원
- 저장 용량을 늘리는 과정이 매우 간단, 삭제도 간단, 하지만 검색할 때 매우 느림
- 배열보다 메모리 공간 측면에서 훨씬 유리함
- Deque (덱)
- Queue 인터페이스를 확장함
- 스레드 그룹
- 실행중인 스레드의 갯수,
- 그룹의 갯수.
- 이름.
- 부모 스레드 그룹,
- 상태 정보,
- 데몬으로 지정,
- 다른 스레드를 스레드 그룹에 포함 등을 수행할 수 있다.
- 스레드
- IO
- 데이터 스트림, 직렬화 및 파일 시스템을 통한 시스템 입력 및 출력을 제공함.
- 바이트
- File 클래스 : 파일 뿐만 아리나 경로 정보도 포함. 심볼릭 링크와 같은 유닉스 계열의 파일에서 사용하는 몇몇 기능을 제대로 제공하지 못해서 nio.file 패키지에 files 라는 클래스에서 일부 대체 메소드를 제공
- 주요 기능
- 존재하는지, 파일인지 경로인지, 읽거나 쓰거나 실행할 수 있는지, 언제 수정되었는지
- 이름을 바꾸고 삭제하고생성하고 전체 경로를 확인
- 해당 경로에 있는 파일의 목록, 경로를 생성, 경로를 삭제하는 기능도 포함
- FileFilter : accept 메서드를 오버라이딩 하여, 매개변수로 순회중인 File이 넘겨짐. 파일의 다양한 정보를 기준으로 필터링 할 때 사용됨.
- FilenameFilter : accept 메서드를 오버라이딩 하여 현재 디렉토리 File 객체와 순회중인 파일의 파일명이 넘겨진다.
- accept() : 배개변수로 넘어온 File 객체가 조건에 맞는지 확인함
- InputSream : 자바의 IO는 기본적으로 InputStream, OutputStream이라는 추상클래스를 통해 제공된다. 데이터 읽기,얼마나데이터가 남았는지,통로 끊기
- 상속 구조 : public abstract class InputStream extends Object implements Closeable
- Closeable 자체가 작업이 종료되면 close를 선언해줘야한다.
- 주요 메소드
- mark : 특정 시점부터 다시 읽을 수 있음. 매개변수를 통해 최대 몇개의 byte를 더 읽을 수 있는지 표시함
- reset : 마크해둔 위치로 돌아감.
- markSupprted : mark, reset 메소드가 수행 가능한지를 확읺마.
- read : 스트림의 현재 위치를 표시해둔다. 매개변수로 넘긴 int는 최대 유효 길이임.
- read : 스트림에서 다음 바이를 읽음. 매개 변수로 넘어온 바이트 배열에 데이터를 담음.
- skip : 매개변수로 넘어온 길이 만큼의 데이터를 건너ㄸ?ㅟㄴ다.
- close : 스트림에서 작업중인 대상을 해제함.
- InputStream을 확장한 주요 클래스
- FileInputStream
- 파일을 읽는데 사용함. 이미지와 같이 바이트코드로 된 데이터를 읽을 때 사용함
- FileInputStream
- 이 클래스는 다른 입력 스트림을 포함하여 단순히 InputStream클래스가 Override되어 있다.
- ObjectInputStream
- FileInputStream
- OutputStream
- 상속 구조 public abstrct class OuputStream extens Object implements closeable.
- Flushaable 인터페이스에서 flush()함수를 구현하고 있음.
- 현재 버퍼에 있는 내용을 기다리지 말고 무조건 저장하라는 의미이다.
- Stream 파일을 읽거나 쓸 때 네트워크 소켓을 거쳐 통신할 때 쓰이는 추상적인 개념.
- 데이터가 전송되는 통로 (네트워크던, 파일에서 넘어오건, 키도브로 오건 데이터가 오고가는 통로가 스트림이다)
- 상속 구조 : public abstract class InputStream extends Object implements Closeable
- Reader ; char 기반의 문자열을 다루기 위한 클래스.
- public abstract class Reader extends Object implements Readable, Closeable
- Writer :1.1 부터 제공함.
- FileWriter: 매개변수로 넘어온 파일 이름이 파일이 아닌 경로를의미할 때나, 권한 등의 문제로 IOExpcetion을 뱉을 수 있다.
- public abstarct class Writer extends Object implements Appendable, Closeable, Flushable
- Appendable은 각종 문자열을 추가하기 위해 선언됨.
- CharSequence
- 마크업 문자를 사용하여 변형과 가공이 가능한 문자열.
- 인터페이스임, char시퀀스에 대한 균일한 읽기 전용 접근 권한을 제공한다.
- 대표적으로 String, StringBuilder, StringBuffer 등이 있다.
- BufferWriter
- Writer 객체를 매개변수로 받아 객체를 생성한다 .
- Writer에 있는 writer()나 append() 메소드를 사용하여 데이터를 쓰면 메소드를 호출했을 때 마다 파일에 쓰기 때문에 비효율적이다. 그래서 이 단점을 보완하기 위해서 탄생함.
- 버퍼라는 공간에 저장해 두었다가 버퍼가 차게되면 데이터를 저장하도록 도와줌.
- NIO:1.4에서 처음 소개
- New Input/Output의 약자로 채널이 양방향 버퍼를 통해 외부 데이터와 통신함.
- 비동기 / non blocking 방식을 지원함.
- Non Blocking :
- IO작업이 진행되는 동안 프로세스의 작업을 중단시키지 않는 방식.
- flip : limit 값을 현재 position으로 젖아하고 Position을 0으로 이동한다
- mark : 현재 포지션을 기억함
- reset : 마크한 곳으로 이동
- rewind : 0으로 이동. flip과의 차이는 flip은 현재 포지션을 limit으로 설정한다.
- remaing : 현재 위치와 llmit 와의 차이
- hasRemaning : remaing > 0인지 검사
- clear : 버퍼를 지우고 현재 position을 0으로 이동하여 limit 값을 버퍼의 크기로 변경
- Serialzable 직렬화란
- 아무런 구현해야할 메소드가 없다.
- serialVersionUID를 선언해주는게 좋다. 선언하지 않으면 자동으로 생성된다. 해당 객체의 버전을 명시하는데 사용된다.
- 각 서버가 해당 객체가 같은지 다른지를 확인할 수 있도록 하기 위해서는 serialVersionUID로 관리해줘야만 한다. 클래스 이름이 같더라도 이 ID가 다르면 다른 클래스로 인지함.
- 자바 시스템 내부에서 사용되는 Object, DAta를 외부에서도 사용할 수 있게 byte 형태로 변환하는 기술. 힙 또는 스택에 있는 객체 데이터를 바이트 형태로 변환하는 기술
- 역직렬화 : byte로 변환된 데이터를 Object나 Data로 변환하는 기술
- 다른 서버로 객체를 전송하려면 반드시 serializable 인터페이스를 구현해야한다.
- transient 예약어 : 다른 JVM으로 보낼 때 해당 예약어로 선언한 변수는 Serializable 대상에서 제외된다. 패스워드나 보안 정보를 제외하고 싶을 때 사용함. 다양한 이유로 해당 데이터만 전송하고 싶지 않을 때 사용함
- Buffer
- jvav.nio.Buffer 클래스를 확장하여 사용한다
- 채널 : 스트림과 비슷한 개념. 하지만 스트림은 단방향 데이터를 전송하기 위해 사용함. 채널은 양방향.
- 버퍼 : 입출력 데이터를 임시로 저장할 때 사용함
- Selector : 하나의 스레드에서 다중의 채널로부터 들어오는 입력 데이터를 처리할 수 있도록 해주는 멀티플렉서. 넌블록킹 입출력을 위한 핵심 개념
- Capacity() : 버퍼의 크기를 나타냄
- limit() : 읽거나 쓸 수 없는 위치를 나타냄
- position() : 현재의 버퍼 위치를 리턴
- 0 <= position <= limit <= 크기
- NIO2
- 자바 1.7에서 소개, 오리지날 File IO의 부족함을 보충. io, nio 사이의 일관성 없는 클래스 설계를 바로잡고, 비동기 채널 등의 네트워크 지원을 대폿 강화
- 모든 파일 시스템을 동일한 방식으로 처리함.
- 파일시스템은 NIO2를 확장해서 제공함. 파일 시스템에 대한 기본 구현을 활용할 수 있고, 파일 시스템 각각구현체를 사용할 수 있다.
- NIO2에서 File 클래스에서 대체하는 클래스들
- Paths : 이 클래스에서 제공하는 static한 get() 메소드를 사용하면 Path라는 인터페이스의 객체를 얻을 수 있다. 여기서 Path라는 인터페이스 파일과 경로에 대한 정보를 갖고 있다.
- Files : 기존 File 클래스에서 제공되던 클래스의 단점들을 보완한 클래스, 매우 많은 메소드를 제공하고, Path를 사용하여 파일을 통제하는데 사용된다.
- FileSystems : 현재 사용중인 파일 시스템에 대한 정보를 처리하는데 필요한 메소드를 제공함. Paths와 마찬가지로 이 클래스에서 제공되는 static한 getDefault() 메소드를 사용하면 현재 사용중인 기본 파일 시스템에 대한 정보를 갖고 있는 FileSystem이라는 인터페이스의 객체를 얻을 수 있다.
- FileStore : 파일을 저장하는 디바이스, 파티션, 볼륨 등에 대한 정보들을 확인하는 데 필요한 메소드를 제공함.
- 위의 모든 클래스들은 java.nio.file이라는 새로 추가된 패키지에 위치함.
- WatchService
- lastModifeied()의 단점 개선, 자바 7부터 등장
- 누군가가 해당 디렉터리에 파일을 생성하거나, 수정하거나 삭제한 사실을 알려준다.
- 파일과 관련된 새로운 API
- SeekableByteChannel (Random access)
- 채널은 디바이스, 파일, 네트워크 등과의 연결 상태를 나타내는 클래스이다.
- 파일을 읽거나 네트워크에서 데이터를 받는 작업을 처리하기 위한 통로
- 자바7부터 추가된 이 인터페이스는 java.nio.channels 선언되어 있으며, 바이트 기반의 채널을 처리하는데 사용됨. 현재 위치를 관리하고 해당 위치가 변경되는 것을 허용하도록 되어 있다.
- 채널을 보다 유연하게 처리하는데 사용
- NetworkChannel
- 네트워크 소켓을 처리하기 위한 채널.
- 네트워크 연결에 대한 바인딩, 소켓업션을 셋팅하고, 로컬 주소를 알려주는 인터페이스
- MuticastCannel
- IP 멀티캐스트를 지원하는 네트워크 채널.
- IP를 그룹으로 묶고, 그 그룹에 데이터를 전송하는 방식
- Asynchoronus I/O
- 자바스크립트의 AJAX도 여기에 속함.
- 자바에서는 스레드를 구현하지 않는 이상 비동기 처리가 어렵다.
- 위의 인터페이스로 처리한 결과는 java.util.concurrent 패키지의 Future 객체로 받게 된다.
- Future로 받지 않으면 CompletionHandler라는 인터페이스를 구현한 객체로 받을 수도 있다.
- AsnychoronuosChannelGroup
- 비동기적인 처리를 하는 스레드 풀을 제공하여 보다 안정적으로 비동기적인 처리가 가능함.
- JDBC 4.1
- RowSetFactory, RowSetProvider 클래스 추가
- 아주 쉽게 Connection, Statement 객체를 생성할 필요 없이 SQL Query를 수행할 수 있다.
- RowSetFactory, RowSetProvider 클래스 추가
- TransferQueue 추가
- java.util.concurrent 패키지에 TransferQueue가 추가됨.
- 어떤 메세지를 처리할 대 유용하게 사용할 수 있음.
- Producer/Consumer 패턴 : 특정 타입의 객체를 처리하는 스레드풀을 미리 만들어 놓고 해당 풀이 객체들을 받으면 처리하도록 하는 구조 의미.
- 보다 일반화하여 SynchronousQueue의 기능을 인터페이스로 끌어올리면서 좀 더 일반화 해서 BlockingQueue를 확장한 것
- Objects 클래스 추가
- 기존과 거의 유사하나, 매개변수로 넘어오는 객체가 null이라 할지라도 예외 발생하지 않도록 구현해놓음.
- SeekableByteChannel (Random access)
- TCP 연결 기반 프로토콜 Trarnsmission Control Protocol
- Socket 클래스 : java.net 패키지에 선언.
- 데이터를 보내는 쪽에서 객체를 생성함. 데이터를 받는쪽에서 요청을 받으면 Socket 객체를 생성하여 데이터를 처리함. 연결 상태를 보관하는 역할
- 소켓의 통신 방식
- 1. 클라이언트에서 Scoket 클래스를 생성함 bind()를 통해 특정 포트를 리슨
- 2.서버에서는 클라이언트의 접속을 체크만 하는 ServerSocket 을 생성.(여러 클라이언트를 인식함. ) 그 다음 accpet()을 실행함. 데이터를 받을 수 있는 상태가 됨
- 3.클라이언트는 OutputStream을 통해 데터 송수신, 서버는 InputStream을 통해 데이터 송수신
-
- 예외 :
- java.net.BindException
- 동일한 port 사용 불가
- connectionException
- 서버를 띄우지 않고 클라이언트 프로그램만 실행했을 때 발생함
- 서버에서는 데이터를 어떻게 받을까 ?
- ServerSocket : 포트를 지정할 수 있고 backlog(큐) 갯수를 지정할 수 있다.(기본값 50개)
- InetAddress라는 클래스의 객체인 bindAddr이 있는데 이는 특정 주소에서만 접근 가능하도록 지정할 때 씀
- accept() : 새로운 소켓 연결을 기다림. 연결되면 Socket 객체를 리턴.
- close() : 소켓 연결을 종료. close 메소드를 처리핮 ㅣ않고 JVM이 계속 동작중이면 해당 포트는 동작하는 서버나 다른 프로그램에서 사용할 수 없다.
- 데이터를 보내는 클라이언트 쪽에서는 Socket 객체를 직접 생성해야만 한다.
- 예외 :
- Socket 클래스 : java.net 패키지에 선언.
- UDP
- DatagramSocke
- 생성자
- 소켓 객체 생성 후 사용 가능한 포트로 대기
- 사용자가 지정한 SocketImpl 객체를 사용하여 소켓 객체만 생성
- 소켓 객체 생성 후 지정된 port로 대기
- 소켓 객체 생성 후 address와 port를 지정하는 서버에 연결
- 소켓 객체 생성 후 address에 지정된 서버로 연결
- receive() : 메소드 호출 시 요청을 대기하고, 만약 데이터를 받았을 때에는 packet 객체에 데이터를 저장
- send() : packet 객체에 있는 데이터 전송
- 생성자
- DatagramSocket
- 특정 포트로 대기할 수 있고, 사용가능한 포트로도 대기할 수 있다. address를 지정할 수도 있음
- 대기할 때는 receive()를 통해 요청을 대기하고, 받을 때는 packet 객체에 데이터를 저장
- send는 객체에 있는 데이터 전송
- DatagramPacket
- length의 크기를 갖는 데이터를 받기 위한 객체를 생성
- 지정된 address와 port로 데이터를 전송하기 위한 객체 생성
- 버퍼의 offset이 할당되어 있는 데이터를 전송하기 위한 객체 생성
- 버퍼의 offset이 할당되더 있고, 지정된 address와 port로 데이터를 전송하기 위한 객체 생성
- 버퍼의 offset이 할당되어 있고, 지정된 소켓 address로 데이터를 전송하기 위한 객체 생성
- 지정된 소켓 address로 데이터를 전송하기 위한 객체 생성
- 예
- server = new DatagramSocket(9999); // port 번호를 지정하여 생성
- DatagramPacket packet = new DatagramPacket(buffer, bufferLength); // 데이터를 받기 위한 DatagramPacket 객체를 byte 배열과 크기로 지정하여 생성
- server.receive(packet); // 데이터를 ㅂ다기 위해서 대기하고 있다가, 데이터가 넘어오면 packet 객체에 데이터를 담는다
- int dataLength = packet.getLength(); // 데이터를 받기 위해서 대기하고 있다가, 데이터가 넘어오면 packet 객체에 데이터를 담는다.
- String data = new String(packet.getData(), 0 ,dataLength); // 전송받은 데이터의 크기를 확인한다
- server.close(); // 모든 처리가 끝나면 socket 객체를 닫는다.
- TCP와 다르게 받는 역할, 보내는 역할 동시 수행 가능하다.
- DatagramSocke
- FilterInputStera
- Java 7에서 달라진 점
- 숫자 표시 방법 보완
- 0x를 통해 16진수로 표현 가능
- 0b를 통해 2진수로 표현 가능
- int million = 1_000_000으로 표현 가능
- Switch 문에서 String 사용
- 6까지는 정수만 사용 가능했다
- 제너릭에서 쉽게 사용할 수 있는 Diamond
- 7부터 생성자에 타입 명시할 필요 없음
- 에외 처리시 다중 처리 가능
- 예전에는 catch를 나열하면서 예외처리해야한느 불편함이 있었다.
- | 를 통해 역슬래쉬를 통해 이처럼 간단하게 처리할 수 있게 됨.
- Non reifiable varag타입
- 자바의 제네릭을 사용하면서 발생 가능한 문제중 하나
- 이 문제는 자바에서 제너릭을 사용하지 않는 버전과의 호환성을 위해서 제공했던 기능 때문에 발생.
- Reifiable : Runtime시에 완전하게 오브젝트를 표현할 수 있는 타입. 즉 컴파일 단계에서 Type erasure에 의해 지워지지 않는 타입 정보를 말함.
- 즉, 실행시에도 타입 정보가 남아있는 타입을 의미하고, non reifiable은 컴파일시 타입 정보가 손실되는 타입을 말한다.
- Primitive 타입 (Int, double, Floatm Byte)
- Number, Integer와 같은 일반 클래스와 인터페이스 타입
- Unbounded Wildcard가 포함된 Parameterized Type
- Raw Type
- 제너릭을 사용하면서 발생 가능한 문제중 하나. non reifiable varags type 문제
- 제네릭을 사용하지 않는 버전과의 호환성을 위해서 제공했던 기능 때문에 발생
- 큰문제는 발생하지 않지만 잠재적으로 문제가 발생할 수 있다.
- 따라서 경고를 없애기 위해서 @SafeVarags라는 어노테이션을 메소드 선언부에 추가하면 된다.(자바 7부터 추가)
- 가변 매개변수를 사용하고
- final이나 static으로 선언되어 있어야 한다.
- 아래 조건에서 컴파일 경고 발생
- 해당 어노테이션은 가변 매개변수가 reifiable 타입이고
- 메소드 내에서 매개 변수를 다른 변수에 대입하는 작업을 수행하는 경우
- Closable
- java 7부터는 꼭 닫지 않아도 되는 애들이 있음
- 5부터 추가된 Closable이라는 인터페이스는 close()를 통해 명시적으로 닫아줘야만 했었다
- public interface Closeable extends AutoCloseable을 통해 인터페이스를 확장함
- 숫자 표시 방법 보완
- Optional:
- null처리를 보다 간편하게 처리하게 하기 위해서.
- NPE 문제를보다 간편하고 명확하게 처리하기 위해서
- java.util 패키지에 존재
- (상속구조) : public final class Optional <T> extends Object
- (final 클래스는 수정은 가능하지만, 상속해서 확장이 불가능 하다는 뜻이다)
- 하나의 깡통이라고 생각. 물건을 넣을수도, 아무 물건이 없을수도 있음.
- Opional 객체 생성
- Optional.of : value가 null인 경우 NPE
- Opional.ofNullable : value가 null인 경우 비어있는 Optional을 반환
- Optional.empty : 비어있는 옵셔널 객체를 생성. 데이터가 없는 Optional 객체를 생성하려면 이와 같이 empty() 메소드를 사용한다.
- isPresent() : 비어있는지 확인하는 메소드
- ㅎ
- Optional의 중간 처리
- Default Method
- 인터페이스가 default 키워드로 선언되면 인터페이스 내에서도 메소드가 구현될 수 있다.
- 인터페이스는 선언에 초점을 맞춰서 사용하지만, 하휘 호환성 때문이다. 인터페이스에 새로운 메소드를 만드렁야 하는데, 자칫 잘못하면 해당 라이브러리를 사용하는 모든 사람들이 에러가 발생할 수 있어서, 일부를 구현해서 문제가 없도록 하는 것이다.
- Date
- Date, SimpleDateFormatter라는 클래스를 사용하여 날짜를 처리해왔다. 하지만 이들 클래스는 스레드 세이프 하지 않다.
- Date, Calendar -> ZonedDateTime, LocalDate : 불변 객체로 변경됨, 모든 클래스가 연산용 메소드 가지고 있고, 연산시 새로운 불변 객체를 리턴해주고 스레드 세이프 하다
- SimpleDateFormant -> DateTimeFormatter : 스레드 세이프 하고 성능 개선
- TimeZone -> ZoneId, ZoneOffset
- Calendar -> ChorrnFiled. ChronoUnit, int 타입에서 enum 타입으로 변경
- 병렬 배열 정렬 Parallel array Sorting.
- sort()는 단일 스레드로 수행되지만, parrelSort()는 필요에 따라 여러개의 스레드로 나뉘어 작업이 수행된다.
-
- 병렬 배열 정렬, Fork-Join 프레임 웍이 내부적으로 이용된다. (이전 글 참고)
- Arrays 클래스에서는
- bindartSerach() 배열 내에서의 검색
- copyOf 배열 복제
- equals 배열 비교
- fill 배열 채우기
- hashCode 배열의 해시코드 제공
- sort 정렬
- toString 배열 내용 출력
- StringJoiner
- 순차적으로 나열되는 문자열을 처리할 때 사용함.
- String("a". "b", "c")
- StringJoiner(",")
- joiner.add(string) 이렇게 하면
- a,b,c라는 결과 얻을 수 있음. 문자열 사이에만 ,를 넣어준다. 맨뒤에 컴마는 알아서 제거해준다.
- Lamnda
- 자바 8부터 사용되는 개념, 익명함수라ㄷ고도 함
- (파라미터) -> 몸체
- 몸체에서 return을 생략할 수 있다.
- 함수형 인터페이스(메소드가 하나만 존재하는 인터페이스)
- 사용 이유 : 자바의 람다식은 함수형 인터페이스로만 접근이 가능함.
- @FunctionalInterface 어노테이션을 선언해야함
- Predicate : test() 라는메소드가 있고 두개의 객체를 비교할 때 사용되고 Boolean을 리턴. and, negate or 이라는 default 메소드가 구현되어 있으며 isEqaul()이라는 static 메소드도 존재
- Predicate<Integer> isBiggerThanFive = num -> num > 5;
- System.out.printin(isBiggerThanFive.test(10)
- Supplier : get() 메소드가 있으며, 리턴값은 generic으로 선언된 타입을 리턴하. 다른 인터페이스들과는 다르게 추가적인 메소드는 선언되어 있지 않음.
- Supplier <String> getString = () -> "Happy new year"
- String str = getString.get();
- System.out.println(str)
- Consumer : accept() 메소드가 있고, T 타입의 객체를 인자로 받고 리턴값은 없음.그냥삼킨다고 이해하면 될듯
- Consumer<String> printString = text -> System.out.println(text + )
- printString.andThen().accppet 이런식으로 두 개 이상의 consumer를 체이닝 할 수 있음
- Function : T 타입 인자를 받고 R 타입 객체를 리턴함
- Function<Integer, Integer> multiply = (value) -> value * 2
- Integer result = multiplt.apply(3);
- System.out.println(result)
- UnaryOperator : 인수 1개를 받아, 인수와 같은 타입의 값을 리턴하는 함수를 의미
- UnaryOperator<String> toLower = (s) -> (s.toLowerCase();)
- BinaryOperator : 인수 2개를 받아 인수와 같은 타입의 값을 리턴하는 함수를 의a
- 입력 인수와 반환값의 타입이 같다
- 두 인수는 타입이 같아야 한다.
- BinaryOperator<Integer> add = (a,b) -> a+b
- Runnable : 인자를 받지 않고 리턴값도 없는 인터페이스
- 추상메소드가 한개만 선언되어야 함
- interface로 선언되어야 한다.
- Predicate : test() 라는메소드가 있고 두개의 객체를 비교할 때 사용되고 Boolean을 리턴. and, negate or 이라는 default 메소드가 구현되어 있으며 isEqaul()이라는 static 메소드도 존재
- stream : 람다를 활용하여 배열 또는 컬렉션에 함수 여러개를 조합하여 원하는 결과를 필터링 하고 가공된 결과를 얻는 것.
- 스트림 생성
- 컬렉션의 목록을 스트림 객체로 변환함. Collection 인터페이스에 stream() 이 선언되어 있음
- 연산의 종류
- 중간 연산
- filter(pred) : 데이터를 조건으로 거를 때 사용함
- map(mapper ) : 데이터를 특정 데이터로 변환
- forEach : for 루프를 수행하는 것처럼 각각의 항목을 꺼냄
- flatMap : 중첩 구조를 한단계 제거하기 위한 중간 연산자. 차원을 1차원으로 낮춰줌. 스트림의 형태가 배열과 같은 때 모든 원소를 단일 원소 스트림으로 반환할 수 있음.
- sorted : 데이터 정렬 . Comparable 인터페이스가 구현되어 있어야 사용 가능함.
- sorted(Comparator.reverseOrder()
- distinct : 중복되는 아이템들을모두 제거해서 새로운 스트림 반환
- peek : forEach와 같은데 반드시 종단 연산이 호출되어야 함.
- limit : 일정 갯수만큼 가져와서 새로운 스트림을 리턴해줌.
- skip : limit과 반대이다, 일정 갯수를 건너띄고, 리턴해줌
- 종단연산
- toArray : 배열로 변환
- any : 일치하는 것을 찾음
- all : 일치하는 것을 찾음
- noneMatch : 일치하는 것을 찾음
- findFrist : 맨 처음이나 순서와 상관없은ㄴ 것을 찾음
- Any : 순서와 상관없는 것을 찾음
- cumulate : 결과를 취합
- reduce : 결과를 취합함
- collect : 원하는 타입으로 데이터를 리턴
- 중간 연산
- 메소드 참조
- :: 더블 콜콜은 Method Reference라고 부른다
- static 메소드 참조 ContainClass :: staticMethodName
- 특정 객체의 인스턴스 메소드 참조 ContaingObject :: instantnaceMethodName
- 특정 유형의 임의의 객체에 대한 인스턴스 메소드 참조 : ContaningType :: meth odName
- 생성자 참조 : ClassNAme :: new
- 스트림 생성
- stream.forEach
- map : 중개 연ㅅ간에 해당함.
- 예) 값을 3배로 바꿔서 출력하기
- list,stream().map(x->x*3).forEach(System.out::println);
- 예) 특정 객체에서 변수만 뽑아내고 싶을 경우
- list.stream().map(student -> student.getName()).collect(Collector.toList())
- (collect()는 모든 값들을 한곳으로 모으는 종단연산임)
- filter : 스트림 내 요소들을 하나씩 걸러내는 작업. Predicate를 활용
- names.stream().filter(name -> name.contains("a"))
- 스트림의 각 요소에 대해 조건문을 실행함. true인 조건문만 남긴다.
- jar
- 여러개의 클래스파일들을 하나의 파일로 묶기 위해서 사용함. 압축파일이라고 생각하면 편함.
- -c 생성, -u 수정, -x 풀기, -t 파일 목록 확인하기
- -f 파일명 지정, -v versove 로그 출력, -m manifest 파일 지정
- calsspath
- jar파일들을 만들어 놓으면 수많은 클래스들을 일일이 다운로드 복사할 필요 없이 하나의 파일들만 다운 받으면 된다.
- $ java -classpath c: /dASDfsld 이렇게 클래스패스에 디렉터리만 설정 해주면, 해당 디렉터리는 프로그램을 실행하는 기본 위치가 된다. -cp라고 줄여서 써도 된다.
- 자바 컴파일 옵션
- -d : javac는 클래스가 있는 디렉터리에 클래스 파일을 생성한다 이 옵션을 제공하면, 해당 디렉토리도 생성하고, 관련된 패키지 디렉토리도 생성하여 클래스 파일을 만들어준다.
- -deprecation : deprecatede된 클래스에 대한 상세한 정보를 포함하여 컴파일 한다.
- -g : 디버깅과 관련된 정보를 포함한 클래스 파일을 생성한다. 운영용으로 컴파일할 땐 이 옵션을 사용할 일은 없지만, 프로파일링 툴 등으로 분석할 일이 있을 때에는 이 옵션을 사용하여 컴파일 해야한다.
- 자바의 표준 실행 옵션 종류
- -client :
- -server
- -cp
- -verbose
- -verboseage
- -version
- -showversion
- -d32
- -Xms
- -Xmx
- -Xss
- javadoc
- 코드를 작성할 때 주석을 달면 해당 내용을 API 문서로 자동 생성 해주는 프로그램
- java, javac와 마찬가지로 jdk/bin 디렉터리에 존재함
- 자바 유틸
- Formatter
- 문자열을 쉽게 처리할 수 있는 클래스
- 기본적인 사용법은 MessageFormat과 유사함.
- explicitIndexing : %1$s 이런식으로 매개변수들의 순서를 명시, 이렇게 % 뒤에 숫자가 있는것은 매개변수의 순서를 의미한다.
- releativeIndexing : %<s로 지정하면 앞서 지정한 것의 위치 값을 그대로 사용한다는말. 첫번째 위치를 그대로 참조
- ordinaryIndexing :
- 일반적인 문자열과 숫자 형식 :
- 날짜와 시간 형식 :
- 그 외의 기타 간단한 형식
- 숫자 및 통화, 날짜 시간, 문자열 등을 위한 클래스
- NumberForrmat : 숫자와 통화를 쉽게 표현
- 현재 JVM의 기본 지역으로 일반적인 목적의 숫자 제공
- 매갭녀수로 제공된 지역의 숫자 format 제공
- 현재 JVM의 기본지역으로 통화 format 제공
- 매개변수로 제공된 지역으로 통화 format 제공
- 현재 JVM의 기본지역으로 정수 format 제공
- 매개변수로 제공된 지역으로 정수 format 제공
- (JVM의 기본 지역 정보는 JVM이 설치되면서 시스템 환경에 따라 설정된다)
- 자리수 관련 메소드들
- setMaxiumFractionDigits : 소수점 이하의 최대 표시 갯수 지정
- setMaxiumIntegerDigits : 정수형의 최대 표시 갯수 지정
- setMiniumFractionDigits : 소수점 이하의 최소 표시 갯수 지정
- setMiniumIntegerDigis : 정수형의 최소 표시 갯수 지정
- DecimalFormat : 보다 세밀한 표현 가능
- NumberForrmat : 숫자와 통화를 쉽게 표현
- DateFormat : 날짜와 시간을 표시하기 위한 클래스, getInstance 메소드로 객체를 생성해야 한다.
- JVM의 기본지역, 지정된 스타일과 지역에 따라 생성 가능함.
- MessageFormat으로 문자열 쉽게 처리하기
- 문자여릉ㄹ 처리하는 데 사용되는 클래스. java.util의 Formatter와 유사함
- 쉽게 문자열을 치환하여 메세지를 작성할 수 있음.
- 각종 Format 클래스의 집합체라고 보면 됨.
- 지금가지는 단순히 숫자 날짜 시간 표현을 하나의 문자열로 리턴해주는 클래스를 사용했지만, 단 하나의 문자열로 문자열 숫자 날짜 시간을 리턴해주는 클래스이다. "자바님이 구매한 총액은 120,585원 입니다" 이런 문자열 만들 때 편함
- Date : 날짜를 처리하기 위함. 1.0 버전에서 추가, 1.1ㅇ[서는 Calendar 클래스를 사용하도록 변경됨.
- Calendar : 추상 클래스,
- Arrays : 배열을 쉽게 처리해주는 클래스
- 정렬, 검색, 비겨ㅛ, 데이터변경, 복사ㅡ, 변환, 해시코드, 문자열로 변환
- fill 모든 위치의 값을 하나의 값으로 변경 혹은 특정 범위를 하나의 값으로 변경
- StringTokenizer
- 어떤 문자열이 일정한 기호로 분리되어 있을 때 사용
- 이 클래스는 사용하는 것을 권장하지 않음.
- String에서 split을 사용하면 문자열을 더 쉽게 분리할 수 있음. 정규 표현식을 다르는 구분자를 매개변수로 넘겨주면 파싱하여 배열로 넘겨준다. API 상에서도 split을 사용하는 것을 권장함.
- StringTokenizer(String str) : 기본 구분자로 매개변수로 넘어온 문자열을 나눈다.
- (String str, String delim) : 지정된 구분자로 문자열을 나누다
- (Strings str, String delim, boolean returnDelims) : 마지막 매개변수 값이true면 구분자도 같이 리턴한다.
- Properties
- 속성 파일들을 관리하기 위함
- 어떤 언어, OS를 사용하더라도 설정 파일들이 존재함.
- HashTable을 확장함
- Random : 임의의 값 생성하기 위한 클래스
- BigDecimal : java.math에 속함.
- 자바에서는 IEEE 754 표준을 따름. Float, Double은 근사치를 제공할 뿐이다. 정확한 값을 제공하지 않는다. 그래서 정확한 숫자 계산을 제공하는 클래스를 사용하는 것이 좋다. (돈 같은 것들)
- add, substract, multiplly, substracvt 더하기, 빼기, 고ㅓㅂ하기, 나누기 연산을 지원한다.
- 정수형 연산은 BigInteger 클래스를 이용하면된다.
- Collections : 컬렉션 객체들의 도우미. 모두 static 메소드. 데이터 검색 절렬 순서변경 ㅂ추가, 복사 삭제 추출 비교 타입변환 변경가능여부 속성 변경, 스레드 세이프 여부 속성 추가, 데이터 타입 안전 여부 속성 추가, singleton
- 기본적으로 collection 클래스들은 스레드 세이프 하지 않ㄷ. 그래서 Collections.synchronoized(new Array...) 이런식으로 객체를 생성하면 스레드에 안전한 클래스가 된다.
- Formatter
- ThreadLocal
- 각 스레드에서 혼자 쓸 수 있는 값을 가지게 할 때 사용함. 즉 스레드 단위로 로컬 변수를 할당하는 기능
- 스레드와 관련된 코드에서 파라미터를 사용하지 않고 객체를 전파하기 위한 용도로 주로 사용됨.
- 활용
- Spring Security 에서는 이것을 통해 사용자 인증 정보를 전파함
- 트랜잭션 컨텍스트 전파 트랜잭션 매니저는 트랜잭션 컨텍스트를 전파하는데 사용함
- 스레드세이프 해야하는 데이터 보관
- 주의 : 스레드풀 환경에서 사용할 경우, 변수에 보관된 데이터의 사용이 끝나면 반드시 해당 데이터를 삭제해야함. 그렇지 않으면 올바르지 않은 데이터를 참조할수 있음.
- 스레드 별로 다른 값을 처리해야할 때 사용하면 됨.
- ThreadLocal<Integer> 이렇게 타입을 지정해줘야.함
- volatile
- 한 스레드가 변경한 값이 메모리에 저장되지 않아서 다른 스레드가 이 값을 볼 수 없는 상황을 방지.
- 읽고 쓰는 작업을 메인메모리 상에서 이뤄지도록 함
- 한 스레드는 읽기만 하고 다른 변수는 읽기/쓰기 작업을 하는 경우 사용
- 각 스레드에서 수행되는 변수의 값을 반복적으로 참조할 때에는 메인메모리에 저장되지 않고 CPU 캐시에 저장된다.
- 그래서 서로 다른 CPU캐시
- 스레드에 선언된 인스턴스 변수를 선언하게 되면 volatile로 선언하면 해당 변수 값이 바뀌면 내 값이 바뀌었으니, 너도 바꿔 라고 하는 효과이다.
- 같은 객체에 있는 변수는 모든 스레드가 같은 값을 바라보게 된다.
- JIT 컴파일러가 Optimization을 수행할 때 문제가 발생.
- 스레드가 보다 빠르게 수행할 수 있도록 instanceVariable을 캐시에 두고 최적화가 되어서 이러한 일이 발생한다. 최적화가 되지 않아 캐시간에 데이터가 서로 다른 값을 보지 않으면 volatile을 사용할 필요가 없다
- 스레드풀
- 스레드를 미리 생성해두고 사용자의 요청을 작업큐에 넣고, 작업큐에서 태스크를 미리 생성해놓은 스레드를에게 할당하는것.
- 사용자로부터 들어온 요청을 작업큐에 넣고 스레드풀은 작업큐에 들어온 Task를 미리 생성해놓은 스레드들에게 할당하고, 다 처리한 스레드
- 기본적으로 코어의 갯수와 동일한 갯수의 스레드를 생성함.
- 병목현상이 발생하는 I/O와 데이터베이스 작업이 주로 해당됨
- (스레드 생성비용 64비트 java8 기준 메모리 1MB 예약할당)
- 적정 스레드풀 갯수 = CPU수 *(CPU 목표 사용량) * (1 + 대기시간 / 서비스 시간)
- 종류
- newFixedThreadPool : 주어진 스레드 갯수만큼 생성. 그 수를 유지함. 일부가 종료되면 다시 생성.
- ExecutorService executor = Executors.newFixedThreadPool()
- newCachedThreadPool : 처리할 스레드가 많아지면, 그만큼 스레드를 증가시킴 (최대 : Integer.MAX_VALUE)
- newSingleThreadExecutor : 스레드를 하나만 생성
- newScheduledThreadPool : 특정 시간 이후, 또는 주기적 작업 스레드 사용시 활용
- newFixedThreadPool : 주어진 스레드 갯수만큼 생성. 그 수를 유지함. 일부가 종료되면 다시 생성.
- 사용법
- Executors로 ExeturosService를 생성하였다면, ExecutorService.submit()를 통해 작업을 추가할 수 있다.
- SingleThreadExecutor : 스레드가 1개인 Executor.시퀀셜하게 처리함.
- Future : 예약된 작업에 대한 결과를 알 수 있음.
- 목적(장점)
- 매번 발생하는 작업을 병렬처리 하기 위해 스레드를 생성/수거 할때의 오버헤드(어떤 처리를 할 때 드는 간접적인 시간, 메모리 비용)를 줄일 수 있다.
- 다수의 사용자 요청을 처리하기 위해서
- 단점
- 너무 많은 스레드를 풀에 만들어 놓으면 놀고있는 스레드로 인한 메모리가 낭비되는 상황 발생 가능
- (이에대한 해결책으로 자바에서는 ForkJoinPool을 지원함)
- 데드락 발생 위험.
- 너무 많은 스레드를 풀에 만들어 놓으면 놀고있는 스레드로 인한 메모리가 낭비되는 상황 발생 가능
- 단점 개선 : Java7에서 ForkJoinPool를 Work Stealing 알고리즘을 통해 구현하였음. 스레드풀에서 Fork(나눠서)Join(합친다)ThreadPool이 사용됨 (스레드가 노는 시간을 최대한 줄이기 위한 시도)내부적으로 WorkStealing알고리즘 구현
- Work Stealing Algorithm
- 병렬처리를 위해 전체 작업 목록을 관리하는 작업큐를 사용하면, 작업큐에 접근하는 것 자체가 경쟁이므로 성능 저하 발생할 수 있다.
- 따라서 일정한 갯수의 스레드를 유지하면서, 스레드마다 독립적인 작업큐를 관리하여, 하나의 스레드 큐가 비게 되면 다른 스레드에서 task를 훔쳐올 수 있게 한다.
- 작업을 하나의 큰 작업들로서 제공함
- 첫 스레드가 작업을 가져와 자신의 로컬 큐에 할당 분할한다.
- 로컬큐에서는 덱(양쪽 끝으로 넣었다 뺐다 할 수 있는 구조)으로 구성됨. 각 쓰레드는 한쪽끝에서만 일을함. (스택처럼) 하지만 나머지 한쪽 끝에서는 잡을 스틸하러온 다른 스레드가 접근하게 됨.
- 두번째 스레드가 가져올 작업이 없다면, 첫 스레드의 큐에 있는 분할된 작업을 훔쳐간다. 나머지 스레드도 반복한다.
- 100 -> 50 -> 25 -> 25 정도의 작업이 수행됨.
- 모든 스레드가 일을 종료하는 시간이 비슷해짐.
- Work Stealing Algorithm
- 사용법
- 생성
- ExecutorService구현 객체는 Executors 클래스의 다음 두가지 메소드 중 하나를 이용해 간편하게 생성가능
- 초기 스레드 수 : ExecutorService 객체가 생성될 때 기본적으로 생성되는 스레드 수
- 코어 스레드 수 : 스레드가 증가한 수 사용되지 않은 스레드를 스레드 풀에서 제거할 때 최소한으로 유지해야할 수
- 최대 스레드 수 : 스레드풀에서 관리하는 최대 스레드 수
- ExecutorService구현 객체는 Executors 클래스의 다음 두가지 메소드 중 하나를 이용해 간편하게 생성가능
- 종료
- 스레드풀에 속한 스레드는 비데몬 스레드이기 때문에 main() 메소드가 실행이 끝나도 애플리케이션 프로세스는 종료되지 않는다. 따라서 스레드풀을 강제로 종료시켜 스레드를 해제시켜줘야 한다. (메모리 릭 발생 가능)
- ExecutorService 구현객체에서는 3개의 종료 메소드를 제공함
- shutDown() : 작업큐에 남아있는 작업까지 모두 마무리 후 종료
- showdownNow() : 작업 잔량 상관없이 강제 종료.
- awaitTermination : timeout 시간안에 처리하면 true리턴, 처리하지 못하면 작업스레드들을 interrupt 시키고 false 리턴
- ForkJoinPool : 큰 태스크를 작은 태스크로 쪼개고 각기 다른 코어에서 병렬적으로 처리후 결과를 취합하는 방식. 내부적으로 Work Stealing 알고리즘이 구현되어 있음. (Devide and Conquer과 흡사.)
- 인터페이스 (Devide and Conquer 활용 재귀적으로 테스크를 쪼개고 합치는 방법). 다른스레드와의 작업 부하의 균형을 맞춤.
- ForkJoinPool는 두가지 방법 제공
- RecursiveAction 클래스
- 반환값이 없는 작업을 구현할 때 사용함
- RecursiveTask 클래스
- 반환값이 있는 작업을 구현할 때 사용함
- 공통점
- compute()라는 추상 메소드 제공.
- task를 분할하는 로직, 더이상 분할할 수 없을 때 subtask의 결과를 생산하는 로직 두개로 나뉜다
- compute()로 재귀적으로 작업을 나누고 fork()로 작업큐에 넣는 작업이 계속 반복된다.
- fork() : 해당 작업을 스레드 풀의 작업 큐에 넣는다. 비동기적으로 실행됨. (execute())
- join() : 해당 작업의 수행이 끝날 때 까지 기다렸다가, 수행이 끝나면 그 결과를 반환함. 동기 메서드
- compute()라는 추상 메소드 제공.
- static final ForkJoinPool mainPool = new ForkJoinPool();
- mainPool.invoke()
- 이를 통해 수행하는 객체를 넘겨주면 작업이 시작됨.
- RecursiveAction 클래스
- ForkJoinPool는 두가지 방법 제공
- 생성
이번 포스트에서 다루는 내용은 다음과 같습니다. 아는 내용이라면 다음 포스트를 살펴보시는게 좋습니다.
- 생성하기
- 배열 / 컬렉션 / 빈 스트림
- Stream.builder() / Stream.generate() / Stream.iterate()
- 기본 타입형 / String / 파일 스트림
- 병렬 스트림 / 스트림 연결하기
- 가공하기
- Filtering
- Mapping
- Sorting
- Iterating
- 결과 만들기
- Calculating
- Reduction
- Collecting
- Matching
- Iterating
스트림 Streams
자바 8에서 추가한 스트림(Streams)은 람다를 활용할 수 있는 기술 중 하나입니다. 자바 8 이전에는 배열 또는 컬렉션 인스턴스를 다루는 방법은 for 또는 foreach 문을 돌면서 요소 하나씩을 꺼내서 다루는 방법이었습니다. 간단한 경우라면 상관없지만 로직이 복잡해질수록 코드의 양이 많아져 여러 로직이 섞이게 되고, 메소드를 나눌 경우 루프를 여러 번 도는 경우가 발생합니다.
스트림은 '데이터의 흐름’입니다. 배열 또는 컬렉션 인스턴스에 함수 여러 개를 조합해서 원하는 결과를 필터링하고 가공된 결과를 얻을 수 있습니다. 또한 람다를 이용해서 코드의 양을 줄이고 간결하게 표현할 수 있습니다. 즉, 배열과 컬렉션을 함수형으로 처리할 수 있습니다.
또 하나의 장점은 간단하게 병렬처리(multi-threading)가 가능하다는 점입니다. 하나의 작업을 둘 이상의 작업으로 잘게 나눠서 동시에 진행하는 것을 병렬 처리(parallel processing)라고 합니다. 즉 쓰레드를 이용해 많은 요소들을 빠르게 처리할 수 있습니다.
스트림에 대한 내용은 크게 세 가지로 나눌 수 있습니다.
- 생성하기 : 스트림 인스턴스 생성.
- 가공하기 : 필터링(filtering) 및 맵핑(mapping) 등 원하는 결과를 만들어가는 중간 작업(intermediate operations).
- 결과 만들기 : 최종적으로 결과를 만들어내는 작업(terminal operations).
생성하기
보통 배열과 컬렉션을 이용해서 스트림을 만들지만 이 외에도 다양한 방법으로 스트림을 만들 수 있습니다. 하나씩 살펴보겠습니다.
배열 스트림
스트림을 이용하기 위해서는 먼저 생성을 해야 합니다. 스트림은 배열 또는 컬렉션 인스턴스를 이용해서 생성할 수 있습니다. 배열은 다음과 같이 Arrays.stream 메소드를 사용합니다.
컬렉션 스트림
컬렉션 타입(Collection, List, Set)의 경우 인터페이스에 추가된 디폴트 메소드 stream 을 이용해서 스트림을 만들 수 있습니다.
그러면 다음과 같이 생성할 수 있습니다.
비어 있는 스트림
비어 있는 스트림(empty streams)도 생성할 수 있습니다. 언제 빈 스트림이 필요할까요? 빈 스트림은 요소가 없을 때 null 대신 사용할 수 있습니다.
Stream.builder()
빌더(Builder)를 사용하면 스트림에 직접적으로 원하는 값을 넣을 수 있습니다. 마지막에 build 메소드로 스트림을 리턴합니다.
Stream.generate()
generate 메소드를 이용하면 Supplier<T> 에 해당하는 람다로 값을 넣을 수 있습니다. Supplier<T> 는 인자는 없고 리턴값만 있는 함수형 인터페이스죠. 람다에서 리턴하는 값이 들어갑니다.
이 때 생성되는 스트림은 크기가 정해져있지 않고 무한(infinite)하기 때문에 특정 사이즈로 최대 크기를 제한해야 합니다.
5개의 “gen” 이 들어간 스트림이 생성됩니다.
Stream.iterate()
iterate 메소드를 이용하면 초기값과 해당 값을 다루는 람다를 이용해서 스트림에 들어갈 요소를 만듭니다. 다음 예제에서는 30이 초기값이고 값이 2씩 증가하는 값들이 들어가게 됩니다. 즉 요소가 다음 요소의 인풋으로 들어갑니다. 이 방법도 스트림의 사이즈가 무한하기 때문에 특정 사이즈로 제한해야 합니다.
기본 타입형 스트림
물론 제네릭을 사용하면 리스트나 배열을 이용해서 기본 타입(int, long, double) 스트림을 생성할 수 있습니다. 하지만 제네릭을 사용하지 않고 직접적으로 해당 타입의 스트림을 다룰 수도 있습니다. range 와 rangeClosed 는 범위의 차이입니다. 두 번째 인자인 종료지점이 포함되느냐 안되느냐의 차이입니다.
제네릭을 사용하지 않기 때문에 불필요한 오토박싱(auto-boxing)이 일어나지 않습니다. 필요한 경우 boxed 메소드를 이용해서 박싱(boxing)할 수 있습니다.
Java 8 의 Random 클래스는 난수를 가지고 세 가지 타입의 스트림(IntStream, LongStream, DoubleStream)을 만들어낼 수 있습니다. 쉽게 난수 스트림을 생성해서 여러가지 후속 작업을 취할 수 있어 유용합니다.
문자열 스트링
스트링을 이용해서 스트림을 생성할수도 있습니다. 다음은 스트링의 각 문자(char)를 IntStream 으로 변환한 예제입니다. char 는 문자이지만 본질적으로는 숫자이기 때문에 가능합니다.
다음은 정규표현식(RegEx)을 이용해서 문자열을 자르고, 각 요소들로 스트림을 만든 예제입니다.
파일 스트림
자바 NIO 의 Files 클래스의 lines 메소드는 해당 파일의 각 라인을 스트링 타입의 스트림으로 만들어줍니다.
병렬 스트림 Parallel Stream
스트림 생성 시 사용하는 stream 대신 parallelStream 메소드를 사용해서 병렬 스트림을 쉽게 생성할 수 있습니다. 내부적으로는 쓰레드를 처리하기 위해 자바 7부터 도입된 Fork/Join framework 를 사용합니다.
따라서 다음 코드는 각 작업을 쓰레드를 이용해 병렬 처리됩니다.
다음은 배열을 이용해서 병렬 스트림을 생성하는 경우입니다.
컬렉션과 배열이 아닌 경우는 다음과 같이 parallel 메소드를 이용해서 처리합니다.
다시 시퀀셜(sequential) 모드로 돌리고 싶다면 다음처럼 sequential 메소드를 사용합니다. 뒤에서 한번 더 다루겠지만 반드시 병렬 스트림이 좋은 것은 아닙니다.
스트림 연결하기
Stream.concat 메소드를 이용해 두 개의 스트림을 연결해서 새로운 스트림을 만들어낼 수 있습니다.
가공하기
전체 요소 중에서 다음과 같은 API 를 이용해서 내가 원하는 것만 뽑아낼 수 있습니다. 이러한 가공 단계를 중간 작업(intermediate operations)이라고 하는데, 이러한 작업은 스트림을 리턴하기 때문에 여러 작업을 이어 붙여서(chaining) 작성할 수 있습니다.
아래 나오는 예제 코드는 위와 같은 리스트를 대상으로 합니다.
Filtering
필터(filter)은 스트림 내 요소들을 하나씩 평가해서 걸러내는 작업입니다. 인자로 받는 Predicate 는 boolean 을 리턴하는 함수형 인터페이스로 평가식이 들어가게 됩니다.
간단한 예제입니다.
스트림의 각 요소에 대해서 평가식을 실행하게 되고 ‘a’ 가 들어간 이름만 들어간 스트림이 리턴됩니다.
Mapping
맵(map)은 스트림 내 요소들을 하나씩 특정 값으로 변환해줍니다. 이 때 값을 변환하기 위한 람다를 인자로 받습니다.
스트림에 들어가 있는 값이 input 이 되어서 특정 로직을 거친 후 output 이 되어 (리턴되는) 새로운 스트림에 담기게 됩니다. 이러한 작업을 맵핑(mapping)이라고 합니다.
간단한 예제입니다. 스트림 내 String 의 toUpperCase 메소드를 실행해서 대문자로 변환한 값들이 담긴 스트림을 리턴합니다.
다음처럼 요소 내 들어있는 Product 개체의 수량을 꺼내올 수도 있습니다. 각 ‘상품’을 ‘상품의 수량’으로 맵핑하는거죠.
map 이외에도 조금 더 복잡한 flatMap 메소드도 있습니다.
인자로 mapper를 받고 있는데, 리턴 타입이 Stream 입니다. 즉, 새로운 스트림을 생성해서 리턴하는 람다를 넘겨야합니다. flatMap 은 중첩 구조를 한 단계 제거하고 단일 컬렉션으로 만들어주는 역할을 합니다. 이러한 작업을 플래트닝(flattening)이라고 합니다.
다음과 같은 중첩된 리스트가 있습니다.
이를 flatMap을 사용해서 중첩 구조를 제거한 후 작업할 수 있습니다.
이번엔 객체에 적용해보겠습니다.
위 예제에서는 학생 객체를 가진 스트림에서 학생의 국영수 점수를 뽑아 새로운 스트림을 만들어 평균을 구하는 코드입니다. 이는 map 메소드 자체만으로는 한번에 할 수 없는 기능입니다.
Sorting
정렬의 방법은 다른 정렬과 마찬가지로 Comparator 를 이용합니다.
인자 없이 그냥 호출할 경우 오름차순으로 정렬합니다.
인자를 넘기는 경우와 비교해보겠습니다. 스트링 리스트에서 알파벳 순으로 정렬한 코드와 Comparator 를 넘겨서 역순으로 정렬한 코드입니다.
Comparator 의 compare 메소드는 두 인자를 비교해서 값을 리턴합니다.
기본적으로 Comparator 사용법과 동일합니다. 이를 이용해서 문자열 길이를 기준으로 정렬해보겠습니다.
Iterating
스트림 내 요소들 각각을 대상으로 특정 연산을 수행하는 메소드로는 peek 이 있습니다. ‘peek’ 은 그냥 확인해본다는 단어 뜻처럼 특정 결과를 반환하지 않는 함수형 인터페이스 Consumer 를 인자로 받습니다.
따라서 스트림 내 요소들 각각에 특정 작업을 수행할 뿐 결과에 영향을 미치지 않습니다. 다음처럼 작업을 처리하는 중간에 결과를 확인해볼 때 사용할 수 있습니다.
결과 만들기
가공한 스트림을 가지고 내가 사용할 결과값으로 만들어내는 단계입니다. 따라서 스트림을 끝내는 최종 작업(terminal operations)입니다.
Calculating
스트림 API 는 다양한 종료 작업을 제공합니다. 최소, 최대, 합, 평균 등 기본형 타입으로 결과를 만들어낼 수 있습니다.
만약 스트림이 비어 있는 경우 count 와 sum 은 0을 출력하면 됩니다. 하지만 평균, 최소, 최대의 경우에는 표현할 수가 없기 때문에 Optional 을 이용해 리턴합니다.
스트림에서 바로 ifPresent 메소드를 이용해서 Optional 을 처리할 수 있습니다.
이 외에도 사용자가 원하는대로 결과를 만들어내기 위해 reduce 와 collect 메소드를 제공합니다. 이 두 가지 메소드를 좀 더 알아보겠습니다.
Reduction
스트림은 reduce라는 메소드를 이용해서 결과를 만들어냅니다. 람다 예제에서 살펴봤듯이 스트림에 있는 여러 요소의 총합을 낼 수도 있습니다.
다음은 reduce 메소드는 총 세 가지의 파라미터를 받을 수 있습니다.
- accumulator : 각 요소를 처리하는 계산 로직. 각 요소가 올 때마다 중간 결과를 생성하는 로직.
- identity : 계산을 위한 초기값으로 스트림이 비어서 계산할 내용이 없더라도 이 값은 리턴.
- combiner : 병렬(parallel) 스트림에서 나눠 계산한 결과를 하나로 합치는 동작하는 로직.
먼저 인자가 하나만 있는 경우입니다. 여기서 BinaryOperator<T> 는 같은 타입의 인자 두 개를 받아 같은 타입의 결과를 반환하는 함수형 인터페이스입니다. 다음 예제에서는 두 값을 더하는 람다를 넘겨주고 있습니다. 따라서 결과는 6(1 + 2 + 3)이 됩니다.
이번엔 두 개의 인자를 받는 경우입니다. 여기서 10은 초기값이고, 스트림 내 값을 더해서 결과는 16(10 + 1 + 2 + 3)이 됩니다. 여기서 람다는 메소드 참조(method reference)를 이용해서 넘길 수 있습니다.
마지막으로 세 개의 인자를 받는 경우입니다. Combiner 가 하는 역할을 설명만 봤을 때는 잘 이해가 안갈 수 있는데요, 코드를 한번 살펴봅시다. 그런데 다음 코드를 실행해보면 이상하게 마지막 인자인 combiner 는 실행되지 않습니다.
Combiner 는 병렬 처리 시 각자 다른 쓰레드에서 실행한 결과를 마지막에 합치는 단계입니다. 따라서 병렬 스트림에서만 동작합니다.
결과는 다음과 같이 36이 나옵니다. 먼저 accumulator 는 총 세 번 동작합니다. 초기값 10에 각 스트림 값을 더한 세 개의 값(10 + 1 = 11, 10 + 2 = 12, 10 + 3 = 13)을 계산합니다. Combiner 는 identity 와 accumulator 를 가지고 여러 쓰레드에서 나눠 계산한 결과를 합치는 역할입니다. 12 + 13 = 25, 25 + 11 = 36 이렇게 두 번 호출됩니다.
병렬 스트림이 무조건 시퀀셜보다 좋은 것은 아닙니다. 오히려 간단한 경우에는 이렇게 부가적인 처리가 필요하기 때문에 오히려 느릴 수도 있습니다.
Collecting
collect 메소드는 또 다른 종료 작업입니다. Collector 타입의 인자를 받아서 처리를 하는데요, 자주 사용하는 작업은 Collectors 객체에서 제공하고 있습니다.
이번 예제에서는 다음과 같은 간단한 리스트를 사용합니다. Product 객체는 수량(amout)과 이름(name)을 가지고 있습니다.
Collectors.toList()
스트림에서 작업한 결과를 담은 리스트로 반환합니다. 다음 예제에서는 map 으로 각 요소의 이름을 가져온 후 Collectors.toList 를 이용해서 리스트로 결과를 가져옵니다.
Collectors.joining()
스트림에서 작업한 결과를 하나의 스트링으로 이어 붙일 수 있습니다.
Collectors.joining 은 세 개의 인자를 받을 수 있습니다. 이를 이용하면 간단하게 스트링을 조합할 수 있습니다.
- delimiter : 각 요소 중간에 들어가 요소를 구분시켜주는 구분자
- prefix : 결과 맨 앞에 붙는 문자
- suffix : 결과 맨 뒤에 붙는 문자
Collectors.averageingInt()
숫자 값(Integer value )의 평균(arithmetic mean)을 냅니다.
Collectors.summingInt()
숫자값의 합(sum)을 냅니다.
IntStream 으로 바꿔주는 mapToInt 메소드를 사용해서 좀 더 간단하게 표현할 수 있습니다.
Collectors.summarizingInt()
만약 합계와 평균 모두 필요하다면 스트림을 두 번 생성해야 할까요? 이런 정보를 한번에 얻을 수 있는 방법으로는 summarizingInt 메소드가 있습니다.
이렇게 받아온 IntSummaryStatistics 객체에는 다음과 같은 정보가 담겨 있습니다.
- 개수 getCount()
- 합계 getSum()
- 평균 getAverage()
- 최소 getMin()
- 최대 getMax()
이를 이용하면 collect 전에 이런 통계 작업을 위한 map 을 호출할 필요가 없게 됩니다. 위에서 살펴본 averaging, summing, summarizing 메소드는 각 기본 타입(int, long, double)별로 제공됩니다.
Collectors.groupingBy()
특정 조건으로 요소들을 그룹지을 수 있습니다. 수량을 기준으로 그룹핑해보겠습니다. 여기서 받는 인자는 함수형 인터페이스 Function 입니다.
결과는 Map 타입으로 나오는데요, 같은 수량이면 리스트로 묶어서 보여줍니다.
Collectors.partitioningBy()
위의 groupingBy 함수형 인터페이스 Function 을 이용해서 특정 값을 기준으로 스트림 내 요소들을 묶었다면, partitioningBy 은 함수형 인터페이스 Predicate 를 받습니다. Predicate 는 인자를 받아서 boolean 값을 리턴합니다.
따라서 평가를 하는 함수를 통해서 스트림 내 요소들을 true 와 false 두 가지로 나눌 수 있습니다.
Collectors.collectingAndThen()
특정 타입으로 결과를 collect 한 이후에 추가 작업이 필요한 경우에 사용할 수 있습니다. 이 메소드의 시그니쳐는 다음과 같습니다. finisher 가 추가된 모양인데, 이 피니셔는 collect 를 한 후에 실행할 작업을 의미합니다.
다음 예제는 Collectors.toSet 을 이용해서 결과를 Set 으로 collect 한 후 수정불가한 Set 으로 변환하는 작업을 추가로 실행하는 코드입니다.
Collector.of()
여러가지 상황에서 사용할 수 있는 메소드들을 살펴봤습니다. 이 외에 필요한 로직이 있다면 직접 collector 를 만들 수도 있습니다. accumulator 와 combiner 는 reduce 에서 살펴본 내용과 동일합니다.
코드를 보시면 더 이해가 쉬우실 겁니다. 다음 코드에서는 collector 를 하나 생성합니다. 컬렉터를 생성하는 supplier 에 LinkedList 의 생성자를 넘겨줍니다. 그리고 accumulator 에는 리스트에 추가하는 add 메소드를 넘겨주고 있습니다. 따라서 이 컬렉터는 스트림의 각 요소에 대해서 LinkedList 를 만들고 요소를 추가하게 됩니다. 마지막으로 combiner 를 이용해 결과를 조합하는데, 생성된 리스트들을 하나의 리스트로 합치고 있습니다.
따라서 다음과 같이 collect 메소드에 우리가 만든 커스텀 컬렉터를 넘겨줄 수 있고, 결과가 담긴 LinkedList 가 반환됩니다.
Matching
매칭은 조건식 람다 Predicate 를 받아서 해당 조건을 만족하는 요소가 있는지 체크한 결과를 리턴합니다. 다음과 같은 세 가지 메소드가 있습니다.
- 하나라도 조건을 만족하는 요소가 있는지(anyMatch)
- 모두 조건을 만족하는지(allMatch)
- 모두 조건을 만족하지 않는지(noneMatch)
간단한 예제입니다. 다음 매칭 결과는 모두 true 입니다.
Iterating
foreach 는 요소를 돌면서 실행되는 최종 작업입니다. 보통 System.out.println 메소드를 넘겨서 결과를 출력할 때 사용하곤 합니다. 앞서 살펴본 peek 과는 중간 작업과 최종 작업의 차이가 있습니다.
공식문서 : "Project Lombok is a java library that automatically plugs into your editor and build tools, spicing up your java.
Never write another getter or equals method again, with one annotation your class has a fully featured builder, Automate your logging variables, and much more."
- 어노테이션 기반으로 코드를 자동완성 해주는 라이브러리
- 장점
- 코드 자동생성을 통한 생상성 향상
- 반복되는 코드를 줄여 가독성 및 유지보수성 향상
- 빌더패턴이나 로그 자동 생성 등 다양한 방면으로 활용 가능
- 단점
- 프로젝트에 참여하는 모든 팀원이 Lombok을 써야함.
- 종류
- 생성자 관련
- @AllArgsConstructor
- 모든 변수를 사용하는 생성자를 자동완성 시켜주는 어노테이션
- @NoArgsConstructor
- 어떠한 변수도 사용하지 않는 기본 생성자를 자동완성 시켜주는 어노테이션
- @RequiredArgsConstructor
- 특정 변수만 사용하여 자동완성 시켜주는 어노테이션
- @Nonnull을 통해 해당 변수를 생성자의 인자로 추가할 수 있음.
- 혹은 final로 선언해도 의존성을 주입받을 수 있다.
- @AllArgsConstructor
- @EqualsAndHashCode
- 클래스에 대한 equals 함수와 hashCode함수를 자동으로 생성해준다.
- 만약 서로 다른 두 객체에서 특정 변수의 이름이 똑같은 경우 같은 객체로 판단을 하고 싶을 때 사용 (동등성 보장)
- @Data
- 공식문서 : All together now: A shortcut for @ToString, @EqualsAndHashCode, @Getter on all fields, and @Setter on all non-final fields, and @RequiredArgsConstructor!
- @ToString, @EaualsAndHashCode, @Getter, @Setter, @RequiredArgsConstructor를 자동완성 시켜준다.
- @Builder
- 공식문서 : ... and Bob's your uncle: No-hassle fancy-pants APIs for object creation!
- 해당 클래스의 객체 생성에 Builder패턴을 적용시켜준다.
- 모든 변수들에 대해 build 하기를 원하면 @Builder를 붙이면 되지만
- 특정 변수만을 build하기를 원한다면 생성자를 작성하고 그 위에 @Builder를 붙여주면 된다.
- *빌더 패턴 :
- 싱글턴, 팩터리 패턴등과 같이 생성 패턴중 하나임.
- 복잡한 객체를 생성하는 방법을 정의하는 클래스와 표현하는 방법을 정의하는 클래스를 별도로 분리하여, 서로 다른 표현이라도 이를 생성할 수 있는 동일한 절차를 제공하는 패턴.
- 이펙티브 자바 설명
- 객체 생성을 깔끔하고 유연하게 하는 기법
- 생성자가 인기가 많을 때 Builder 패턴 적용을 고려하라
- 생성자에 매개변수가 많다면 빌더를 고려하라
- 단점 :
- 다른 생성자를 호출하는 생성자가 많아서, 인자가 추가되면 코드 수정이 어려움
- 코드 가독성이 떨어짐
- 특히 인자수가 많아지면 코드가 길어지고 읽기 어려워짐.
- *자바빈 패턴
- 빌더패턴의 대안
- setter 메소드를 통해 가독성을 향상시킴
- 장점
- 각 인자의 의미를 파악하기 쉬워짐
- 복잡하게 여러 개의 생성자 만들지 않아도 됨
- 단점
- 객체의 일관성이 깨짐(1회의 호출로 객체 생성이 안끝남)
- setter가 있으므로 immutable한 클래스 생성 불가.
- 생성자 관련
// 빌더 패턴
Member customer = Member.build()
.name("홍길동")
.age(30)
.build();
// 자바빈 패턴
NutritionFacts cocaCola = new NutritionFacts();
cocaCola.setServingSize(240);
cocaCola.setServings(8);
cocaCola.setCalories(100);
cocaCola.setSodium(35);
cocaCola.setCarbohdydrate(27);-
- @Delegate
- 한 객체의 메소드를 다른 객체로 위임시켜줌.
- 특정 인터페이스 정보를 이용하여 위임할 클래스에 있응 메소드들을 위임받을 클래스들에게 위임키시게 된다.
- @Delegate
public class DelegationExample {
@Delegate(types=List.class)
private final List<string> names = new ArrayList<string>();
}
// 위는 아래 코드와 일치함
public class DelegationExample {
private final List<string> names = new ArrayList<string>();
public boolean add(final String item) {
return this.names.add(item);
}
public boolean remove(final String item) {
return this.names.remove(item);
}
//...그 외의 List의 메쏘드들
}
-
- @Log
- Captain's Log, stardate 24435.7: "What was that line again?"
- @Log4j2를 이용하면 해당 클래스의 로그 클래스를 자동으로 완성시켜준다.
- 그 외 기타
- @Cleanup
- Automatic resource management: Call your close() methods safely with no hassle.
- IO 처리나 JDBC 코딩을 할 때 try-catch-finally 문의 finally 절을 통해서 close() 메소드를 해줘야 하는게 여간 번거로운 일이 아니었다.
- 위 어노테이션을 통해 해당 자원이 자동으로 닫히는 것을 보장한다
- @ToString
- No need to start a debugger to see your fields: Just let lombok generate a toString for you!
- Class에 있는 필드들을 검사해서 문자열로 변환해주는 toString() 메소드를 생성함.
- @Value
- Immutable classes made very easy.
- Immutable Class를 생성해줌.
- @Data와 비슷하지만 모든 필드를 기본적으로 private , final로 설정하고, setter 함수 생성을 생략
- @Synchonized
- synchronized done right: Don't expose your locks.
- 파라미터로 넘긴 Object 단위로 락을 걸거나, 파라미터로 아무것도 입력하지 않으면 어노테이션이 사용된 메소드 단위로 락을 건다.
- @SneakyThrows
- To boldly throw checked exceptions where no one has thrown them before!
- 메소드 선언부에 사용되는 throws 키워드 대신 사용하는 어노테이션으로 예외 클래스를 파라미터로 입력 받는다.
- checked exceptions을 처리해준다.
- @With
- Immutable 'setters' - methods that create a clone but with one changed field.
- value : 필드의 접근 제어자를 지정함
- onMethod : 메서드의 어노테이션을 추가한다.
- onParam : 파라미터에 어노테이션을 추가한다.
- Immutable 'setters' - methods that create a clone but with one changed field.
- val
- Finally! Hassle-free final local variables
- Local 변수 선언을 val을 이용하면 초기화 값을 이용하여 변수 타입을 유추하여 final로 생성해줌
- (JS에서 var키워드와 동일)
- @Getter(lazy=true)
- Laziness is a virtue!
- You can let lombok generate a getter which will calculate a value once, the first time this getter is called, and cache it from then on. This can be useful if calculating the value takes a lot of CPU, or the value takes a lot of memory. To use this feature, create a private final variable, initialize it with the expression that's expensive to run, and annotate your field with @Getter(lazy=true). The field will be hidden from the rest of your code, and the expression will be evaluated no more than once, when the getter is first called. There are no magic marker values (i.e. even if the result of your expensive calculation is null, the result is cached) and your expensive calculation need not be thread-safe, as lombok takes care of locking.
- 동기화를 이용하여 최초 1회만 호출
- 많은 CPU 사용량혹은 메모리를 점유하는 연산에서 유용하다
- @Cleanup
- @Log
import lombok.Getter;
public class GetterLazyExample {
@Getter(lazy=true) private final double[] cached = expensive();
private double[] expensive() {
double[] result = new double[1000000];
for (int i = 0; i < result.length; i++) {
result[i] = Math.asin(i);
}
return result;
}
}
다음 포스트에서 Lombok의 동작원리까지 살펴보자.
Lombok은 컴파일 시점에 바이트코드를 변환하여 원하는 부분을 주입해주는 방식으로 동작한다.
아래에서 더 자세히 알아보자.
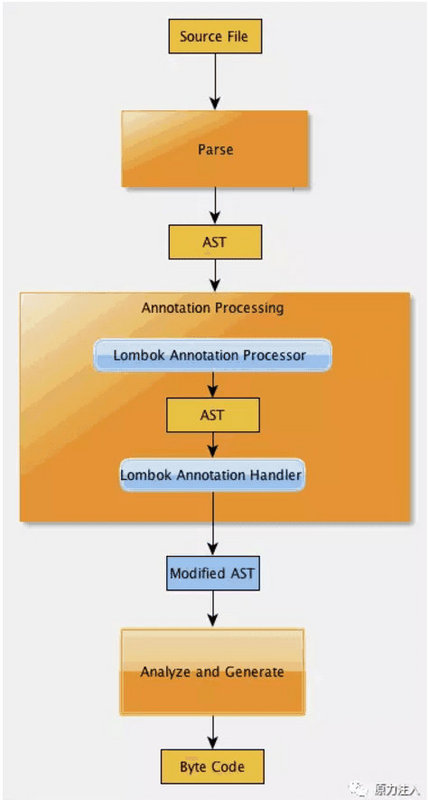
Lombok이 처리되는 과정은 다음과 같다
1. javac는 소스파일을 파싱하여 AST트리를 만든다.
2. Lombok은 AnnotaionProcessor에 따라 AST 트리를 동적으로 수정하고 새 노드(소스코드)를 추가하고 마지막으로 바이트 코드를 분석 및 생성한다.
(컴파일 과정에서 생성된 Syntax Tree는 com.sun.source.tree.*에서 public accesss를 제공한다.)
4. 최종적으로 javac는 Lombok Annotation Processor에 의해 수정된 AST를 기반으로 Byte Code를 생성한다.
코드레벨에서 더 자세히 알아보자
우선 아래의 코드는 lombok.core.AnnotationProcess.java의 process 함수이다.
아래에서 재귀적으로 루트에서부터 순회를 하는 것을 볼 수 있다.
특히 RoundEnvironment의 rootElements()를 통해 자바 컴파일러가 생성한 AST를 참조한다.
(아래 깃헙 레포에서 확인할 수 있다) github.com/projectlombok/lombok/blob/5120abe4741c78d19d7e65404f407cfe57074a47/src/core/lombok/core/AnnotationProcessor.java)
@Override public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
if (!delayedWarnings.isEmpty()) {
// 루트 어노테이션을 참조한다.
Set<? extends Element> rootElements = roundEnv.getRootElements();
// 루트 어노테이션에서부터 순회한다.
if (!rootElements.isEmpty()) {
Element firstRoot = rootElements.iterator().next();
for (String warning : delayedWarnings) processingEnv.getMessager().printMessage(Kind.WARNING, warning, firstRoot);
delayedWarnings.clear();
}
}
for (ProcessorDescriptor proc : active) proc.process(annotations, roundEnv);
boolean onlyLombok = true;
boolean zeroElems = true;
for (TypeElement elem : annotations) {
zeroElems = false;
Name n = elem.getQualifiedName();
if (n.toString().startsWith("lombok.")) continue;
onlyLombok = false;
}
// Normally we rely on the claiming processor to claim away all lombok annotations.
// One of the many Java9 oversights is that this 'process' API has not been fixed to address the point that 'files I want to look at' and 'annotations I want to claim' must be one and the same,
// and yet in java9 you can no longer have 2 providers for the same service, thus, if you go by module path, lombok no longer loads the ClaimingProcessor.
// This doesn't do as good a job, but it'll have to do. The only way to go from here, I think, is either 2 modules, or use reflection hackery to add ClaimingProcessor during our init.
return onlyLombok && !zeroElems;
}
아래에서 RoundEnviroment 인터페이스 코드를 열어보면
getRootElements()가 정의되어 있고, 앞선 round에서 생성된 root 어노테이션을 참조를 리턴한다.
(RoundEnvironment인터페이스는 Annotation processing tool 프레임워크이고, 프로세서가 annotation processing의 라운드를 수정할 수 있도록 도와줌.)
/**
* An annotation processing tool framework will {@linkplain
* Processor#process provide an annotation processor with an object
* implementing this interface} so that the processor can query for
* information about a round of annotation processing.
*
* @author Joseph D. Darcy
* @author Scott Seligman
* @author Peter von der Ahé
* @since 1.6
*/
public interface RoundEnvironment {} /**
* Returns the {@linkplain Processor root elements} for annotation processing generated
* by the prior round.
*
* @return the root elements for annotation processing generated
* by the prior round, or an empty set if there were none
*/
Set<? extends Element> getRootElements();
/**
* Returns the elements annotated with the given annotation type.
* The annotation may appear directly or be inherited. Only
* package elements, module elements, and type elements <i>included</i> in this
* round of annotation processing, or declarations of members,
* constructors, parameters, type parameters, or record components
* declared within those, are returned. Included type elements are {@linkplain
* #getRootElements root types} and any member types nested within
* them. Elements of a package are not considered included simply
* because a {@code package-info} file for that package was
* created.
* Likewise, elements of a module are not considered included
* simply because a {@code module-info} file for that module was
* created.
*
* @param a annotation type being requested
* @return the elements annotated with the given annotation type,
* or an empty set if there are none
* @throws IllegalArgumentException if the argument does not
* represent an annotation type
*/
Set<? extends Element> getElementsAnnotatedWith(TypeElement a);
요약을 하면
Lombok은 컴파일 타임에 AnnotaionProcessor에 따라 AST 트리를 동적으로 수정하고 새 노드(소스코드)를 추가하고 마지막으로 바이트 코드를 분석 및 생성한다.
특히 AnnotationProcessor 코드를 열어보면 RoundEnvironment의 rootElements()를 통해 자바 컴파일러가 생성한 AST를 참조
마지막으로 직접 Lombok을 통해 변환된 코드를 확인해보자.
IntelliJ에서 기본적으로 제공되는 디컴파일러를 이용해 직접 바이트코드를 확인할 수 있다.
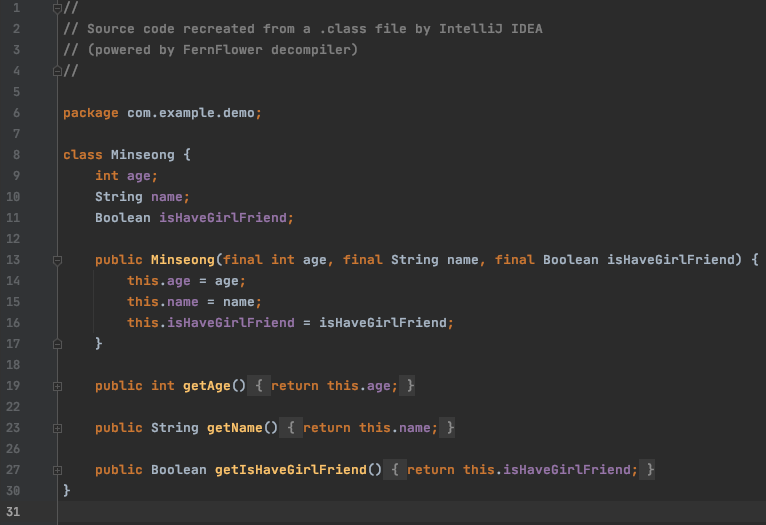
아래와 같이 클래스를 만들고 빌드를 하면
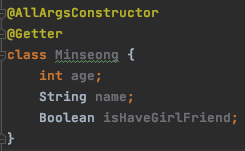
아래의 디렉토리에 .class 파일이 생성된다.
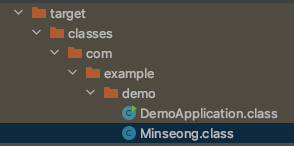
생성된 .class 확인해보면 아래와 같이 Lombok에 의해 모든 변수를 초기화하는 생성자와, getter가 생성된 것을 확인할 수 있다.
추상화된 Lombok의 동작원리를 내부 코드레벨까지 살펴보았다. 이제 어느정도 확신을 가지고 Lombok을 사용할 수 있게 되었다.
<참고>
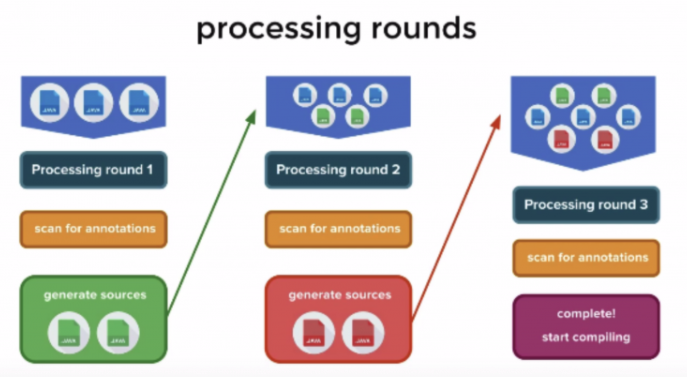
(*아래의 그림처럼 javac에 의해 Annotation은 여러 라운드에 걸쳐 processing 된다.)
*Abstract Syntax Tree 추상구문트리란?
추상이라는 말은 실제 구문에서나타나는 모든 세세한 정보를 나타내지 않는다는 것을 의미함.
주로 컴파일러에서 널리 사용되는 자료구조.
Abstract Syntatic 구조를 표현하기 위해서 사용된다.
Abstract Syntatic이란 프로그래밍 언어의 문법 및 각 문단의 역할을 표현하기 위한 규칙.
프로그래밍 언어의 사용이 틀린 부분이 없는지, 문맥적인 소스코드 검사의 단계에서 사용됨.
알아보기 전에 꼭 알야아 할 키워드들이 있다.
File Desciptor : 리눅스 혹은 유닉스 계열의 시스템에서 프로세스가 파일을 다룰 때 사용하는 개념. 프로세스에서 특정 파일에 접근할 때 사용하는 추상적인 값. 프로세스에서 열린 파일의 목록을 관리하는 테이블의 인덱스.
리눅스(유닉스) 에서는 모든것을 파일로 취급한다.(파일, 소켓 등) 각각의 프로세스는 File desciptors의 테이블을 가지고 있다.
IO multiplexing : 하나의 통신 채널을 통해서 둘 이상의 데이터를 전송하는 기술, 물리적 장치의 효율성을 높이기 위해, 최소한의 물리적 요소만을 이용하여, 최대한의 데이터를 전달하기 위해 사용되는 기술.
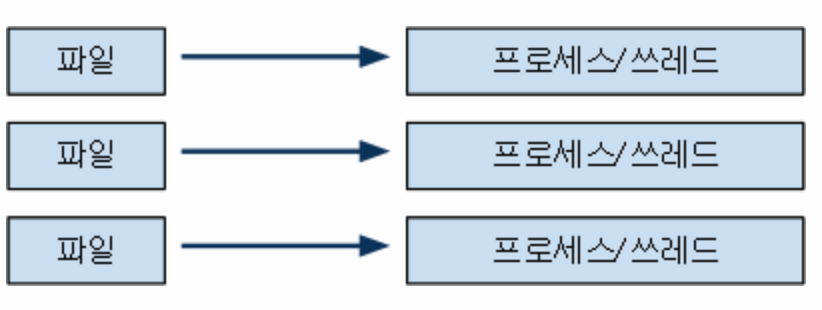
멀티플렉싱이 필요한 이유는, 각 파일을 처리할 때 각각의 io통로를 통로를 만들어 각각의 프로세스와 스레드를 만들게 되면 아래와 같은 단점이 있다.
- 프로세스간의 통신을 위해 IPC가 필요하다.
- 프로세스 동기화, 스레드를 동기화 해야한다.
- 컨텍스트 스위칭 등의 오버헤드가 있을 수 있다.
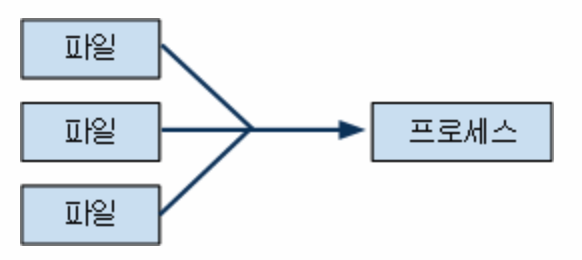
그래서 이와 같은 단점을 보완하기 위해서, 하나의 채널을 통해 둘 이상의 데이터를 송수신 하여, 프로세스의 갯수를 최소한으로 유지하면서 여러개의 파일을 처리하는 방법인 IO 멀티플렉싱이 등장하였다.
위와 같이 멀티플렉싱을 통해 여러개의 파일을 다루기 위해 fd를 배열을 통해 관리한다.
데이터 변경을 감시할 fd를 배열에 넣고, 배열에 포함된 fd에 변경(읽기, 쓰기, 에러)등이 발생하면, fd에 대응되는 배열에 flag를 표시하는 방법으로 동작한다.
즉 개발자는 fd 배열을 통해 여러개의 파일을 감시하고 처리할 수 있게 된다.
System Call : 응용프로그램에서 운영체제에게 시스템 자원을 요청하는 하나의 수단.
- 처리방식 : 시스템콜을 요청하면 제어가 커널로 넘어가여, 내부적으로 각각의 시스템 콜을구분하기 위해 기능별로 고유한 번호를 할당해 놓는다. 그리고 그 번호에 맞는 서비스 루틴을 호출하고, 처리하고 나면 커널 모드에서 사용자 모드로 넘어옴.
- 프로세스제어, 파일조작, 장치관리, 시스템 정보 및 자원관리, 통신 관련등이 있다.
polling : 하나의 장치 또는 프로그램에서 충돌을 피하거나 동기화 처리 목적으로 다른 장치나 프로그램의 상태를 주기적으로 검사해서 일정한 조건을 만족할 때 송수신 등의 자료처리를 하는 방식. 이 방식은 버스와 같이 여러개의 장치가 동일 회선을 사용하는 상황에서 주로 사용함 .
이제 본격적으로 select, poll, epoll에 대해서 알아보자.
*select란
싱글스레드로 여러개의 파일을 작업하고자 할 때 사용할 수 있는 메커니즘.
입출력을 관리하고자 하는 파일의 그룹을 fd_set이라는 파일 비트 배열에 집어넣고, 이 배열의 값이 변했는지 확인하는 방식으로 동작한다.
<sys/select.h>에 아래와 같이 구현되어 있다
int select(int nfds, fd_set *restrict readfds, fd_set *restrict writefds,
fd_set *restrict errorfds, struct timeval *restrict timeout);
성공시 준비된 fd 갯수를 리턴함. 타임아웃시 0, 오류 시 -1을 리턴함.
fd가 입출력을 수행할 준비가 되거나 정해진 시간이 경과할 때 까지 block된다.
매개변수는 아래와 같다.
- ndfs : 감시할 fds의 갯수
- readfds : 읽을 데이터가 있는지 검사하기 위한 파일 목록
- writefds : 쓰여진 데이터가 있는지 검사하기 위한 파일 목록
- exceptfds : 파일에 예외 사항들이 있는지 검사하기 위한 파일 목록
- timeout : 데이터변화를 감시하기 위해서 사용하는 time-out. null이면 계속 대기함.
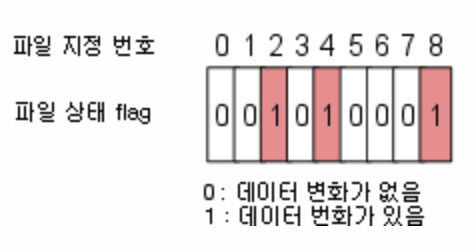
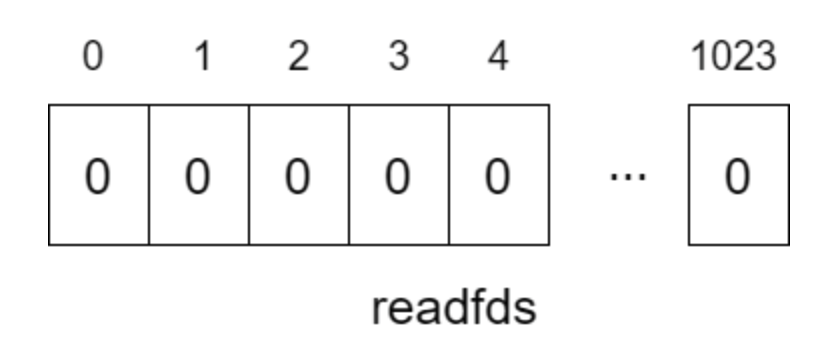
fd_set 구조체는 1024 크기를 가지는 비트 배열을 포함하는데, 파일 지정 번호는 각 비트 배열 첨자에 대응하는 구조를 가지고 있다. 예를 들어 파일 지정번호가 3이면 4번째 비트 배열에 대응된다.
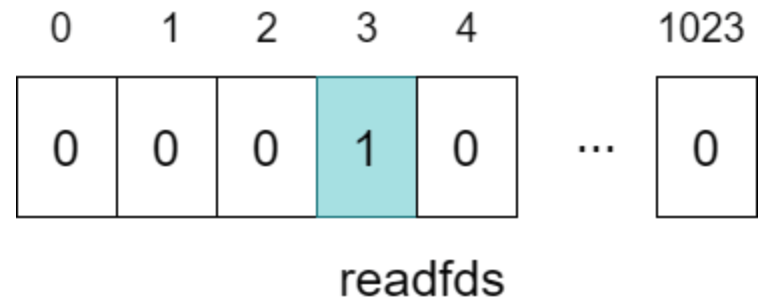
만약 변경된 데이터가 있으면 해당 비트값이 1로 설정되고, 이 비트 값을 검사함으로써 어떤 파일 지정 번호에 변경된 데이터가 있는지 확인해서 읽기/쓰기를 하면 된다.
아래와 같은 매크로를 지원한다.
FD_ZERO(fd_set* set); //fdset 을초기화
FD_SET(int fd, fd_set* set); //fd를 set에 등록.
FD_CLR(int fd, fd_set* set); //fd를 set에서 삭제. 더이상 검사하지 않음.
FD_ISSET(int fd, fd_set* set);//fd가 준비되었는지 확인
아래와 같이 예시의 일부를 보면 while루프 안에서, FD_ISSET매크로를 통해 fd배열에 변화가 있는지 검사하고 있다.
while(1){
FD_SET(fd,&readfds);
ret = select(fd+1, &readfds, NULL, NULL, NULL);
if(ret == -1){
perror("select error ");
exit(0);
}
if(FD_ISSET(fd, &readfds)){
while(( n = read(fd, buf, 128)) > 0)
printf("%s",buf);
}
memset(buf, 0x00, 128);
usleep(1000);
}
그라고 fd_set을 만들어 그 set에 속한 fd중 하나라도 입력이 들어오면 block이 해제되고 원하는 루틴을 수행할 수 있다.
select의 단점
- 감시하고자 하는 이벤트 설정을 변형하기 때문에 매번 이벤트 비트를 새로 설정해야 하는 불편함이 있다.
- fd를 하나하나 체크해야헤서 On의 계산양이 필요함. 따라서 관리하는 fd의 수가 증가하면 성능이 떨어짐
- 사용자가 selector.selectedKeys ()를 호출하면 운영 체제는 모든 소켓을 검색하여 시스템 커널에서 사용자의 메모리로 복사한다. 연결 수가 증가하면 순회 및 복제 시간이 선형 적으로 증가하고 메모리 소비가 증가한다.
- fd 길이에 제한이 있음
*poll이란
함수를 통해 지정한 소켓의 변화를 확인할 때 쓰이는 함수
소켓셋의 저장된 소켓의 변화가 생길 때 까지 기다리고 있다가, 소켓이 어떤 동작을 하면 동작한 소켓을 제외한 나머지 소켓을 모두 제거하고, 해당 데이터 링크의 확립 방법 중 하나이다.
select와 동일하게 단일 프로세스에서 여러 파일의 입출력이 가능함.
select의 단점을 개선함. 관심있는 fd만 넘겨줄 수 있고, 감시하고 있는 이벤트도 보전이 된다.
하지만 감시하고 있는 모든 fd에 대해서 루프를 돌면서 체크를 해야하는 단점은 여전히 존재.
또한 하나의 fd 이벤트를 전송하기 위해 64비트를 전송해야 하는 단점도 있음.
timeval이라는 구조체를 사용해 타임아웃값을 세팅하지만, poll은 별다른 구조체 없이 타임아웃 기능을 지원함.
함수는 아래와 같이 정의 되어 있고, 매개변수에 pollfd라는 구조체가 있다.
int poll(struct poolfd *ufds, unsigned int nfds, int timeout);
pollfd의 구조체에 대해서 알아보면
3개의 멤버 변수가 있고, 이 구조체에 fd를 세팅하고, fd가 어떤 이벤트가 발생할 것인지 이벤트를 지정한다.
그럼 poll은 fd에 해당 events가 발생하는지를 검사하게 되고, 해당 events가 발생하면 revents를 채워서 돌려주게 된다. revents는 events가 발생했을 때 커널에서 이 events에 어떻게 반응했는지에 대한 반응값이다.
struct pollfd
{
int fd; // 관심있어하는 파일지시자
short events; // 발생된 이벤트
short revents; // 돌려받은 이벤트
};
그리고 event, revents는 아래의 값들을 가질 수 있다.
<sys/poll.h>에 디파인 되어 있다.
POLLERR An exceptional condition has occurred on the device or
socket. This flag is output only, and ignored if present
in the input events bitmask.
POLLHUP The device or socket has been disconnected. This flag is
output only, and ignored if present in the input events
bitmask. Note that POLLHUP and POLLOUT are mutually
exclusive and should never be present in the revents bit-mask bitmask
mask at the same time.
POLLIN Data other than high priority data may be read without
blocking. This is equivalent to ( POLLRDNORM | POLLRDBAND
).
POLLNVAL The file descriptor is not open. This flag is output
only, and ignored if present in the input events bitmask.
POLLOUT Normal data may be written without blocking. This is
equivalent to POLLWRNORM.
POLLPRI High priority data may be read without blocking.
POLLRDBAND Priority data may be read without blocking.
POLLRDNORM Normal data may be read without blocking.
POLLWRBAND Priority data may be written without blocking.
POLLWRNORM Normal data may be written without blocking.
poll의 동작 방식은 아래의 시나리오와 같다.
- pollfd에 입력된 fd의 event에 입력 event가 발생하면, 커널은 입력 event에 대한 결과를 되돌려준다.
- 만약, 이 결과는 입력된 event가 제대로 처리되었다면 POLLIN을 리턴해준다. 하지만 에러가 발생하면 POLLERR을 되돌려준다.
- 그러므로 revent를 검사함으로써, 해당 fd에 읽을 데이터가 있다는 것을 알 수 있게 된다.
* epoll
(ms에서는 iocp, freebsd계열에서는 kqueue가 있다)
select의 단점을 극복하기 위해 커널 레벨의 멀티플렉싱을 지원함.
fd에 대한 루프를 돌지 않고, 커널에게 정보를 요청하는 함수를 호출할 때마다 전체 관찰 대상에 대한 정보를 넘기지도 않는다.
또한 epoll_wait함수를 호출하면 관찰 대상의 정보를 매번 전달할 필요가 없다.
이 부분을 직접 운영체제에서 담당하고, 관찰 대상의 저장소를 만들어달라고 OS에 요청하면 그 저장소에 해당하는 fd를 리턴해준다.
관찰 대상 범위가 달라지면 epoll_fd를 통해 확인을 한다. 따라서 전체 fd 리스트를 순회하면서 FD_ISSET을 하지 않아도 된다.
select의 단점을 개선하였지만, 프로세스가 커널에게 지속적으로 IO상황을 체크하여 동기화 하는 개념은 여전히 유효하다.
커널에 관찰대상에 대한 정보를 한번만 전달하고, 관찰댓아의 범위, 또는 내용에 변경이 있을 때만 변경 사항을 알려줌.
커널 공간이 fd를 관리하여 select보다 빠른 이벤트 처리가 가능함.
epoll_create를 통해 epoll 구조체를 생성하고 epoll_ctl을 통해서 디스크립터를 등록 수정 삭제하고, epoll_wait를 통해 파일 디스크립터의 변화를 탐지한다.
위의 동작을 위해서는 3가지 요청이 필요하다.
fd들의 io이벤트 저장을 위한 공간을 만드느 함수. 매개변수로 size만큼의 io이벤트를 저장할 공간을 만든다.
int epoll_create(int size); //size는 epoll_fd의 크기정보를 전달한다.
//반환 값 : 실패 시 -1, 일반적으로 epoll_fd의 값을 리턴
관찰 대상이 되는 fd를 등록, 삭제할 때 사용됨.
int epoll_ctl(int epoll_fd, //epoll_fd
int operate_enum, //어떤 변경을 할지 결정하는 enum값
int enroll_fd, //등록할 fd
struct epoll_event* event //관찰 대상의 관찰 이벤트 유형
);
//반환 값 : 실패 시 -1, 성공시 0
- 매개변수
- epfd : epoll fd값
- op : 관심가질 fd를 등록할지, 등록되어 있는 fd의 설정을 변경할지, 등록되어 있는 fdf를 관심 목록에서 제거할건지에 대한 옵션값.
- EPOLL_CTL_ADD : fd를 목록에 추가. 이미 존재하면 EEXIST에러 발생
- EPOLL_CTL_MOD : fd 설정 변경. 목록에 없으면 ENOENT 에러를 발생시킴
- EPOLL_CTL_DEL : fd를 제거함.목록에 없으면 ENOENT 에러를 발생.
- fd : edfd에 등록할 관심있는 fd값
- event : edfd에 등록할 관심있는 fd가 어떤 이벤트가 발생할 때 관심을 가질지에 대한 구조체. 관찰 대상의 관찰 이벤트 유형. 아래와 같은 구조채로 선언되어 있음.
- 상태변화가 발생한 fd의 정보가 이 배열에 별도로 묶이게 된다.
- 따라서 상태 변화에 대해 일일이 반복문을 돌려 확인할 필요가 없다.
struct epoll_event
{
__unit32_t events;
epoll_data_t data;
};
typedef union epoll_data
{
void* ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;epoll_wait은 관심있는 fd의 변화를 감지한다. 이벤트의 배열을 전달하고, 리턴값은 발생한 사건들의 갯수를 리턴한다는 점에서 select, poll과 차이가 있다.
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout)
- 매개변수
- events: 이벤트가 발생된 fd들을 모아놓은 구조체 배열
- maxevents : 실제 동시 접속수와 상관없이 최대 몇개까지의 event만 처리할 것임을 지정해주도록 함.
- timeout : 밀리세컨드 단위로 지정할 수 있다. -1이면 영원히 기다리는 blocking상태가 되고, 0이면 즉시 조사만 하고 리턴한다.
- 이벤트 탐지 방법
- level : 특정 상태가 유지되는 동안 감지.
- edge trigger : 특정 상태가 변화하는 시점에서만 감지.
더 알아보기
java에서는 epoll을 어떻게 활용할까?
java.nio.channels.SelectorProvider의 Linux의 epoll notification을 활용한다
SelectorProvider :
nio에서 Selector은 여러 SelectableChannel을 자신에게 등록하게 하고
등록된 SelectableChannel의 이벤트 요청들을 나눠서 적절한 서비스 사용자에게 보내 처리하는 멀티플렉스 IO를 가능하게 한다.
특히 새로운 epoll 기반의 SelectorProvider는 예전의 poll 기반의 SelectorProvider 구현보다 더 확장성이 좋다.
리눅스 커널 2.6 이면 디폴트로 epoll기반으로 설정된다. 그 미만의 버전에서는 poll 기반으로 설정됨.
selector* : nio에서 여러개의 채널에서 이벤트를 모니터링 할 수 있는 객체. 하나의 스레드에서 여러 채널에 대해 모니터링이 가능함.
SelectableChannel이 수천개 정도 있을 때 기존의 poll 기반의 SelectorProvider보다 확장성이 뛰어남.
javadoc에 아래와 같이 기술되어 있다.
A new java.nio.channels.SelectorProvider implementation that is based on the
Linux epoll event notification facility is included.
The epoll facility is available in the Linux 2.6, and newer, kernels.
The new epoll-based SelectorProvider implementation is more scalable
than the traditional poll-based SelectorProvider implementation
when there are thousands of SelectableChannels registered with a Selector.
The new SelectorProvider implementation will be used by default
when the 2.6 kernel is detected.
The poll-based SelectorProvider will be used when a pre-2.6 kernel is detected.
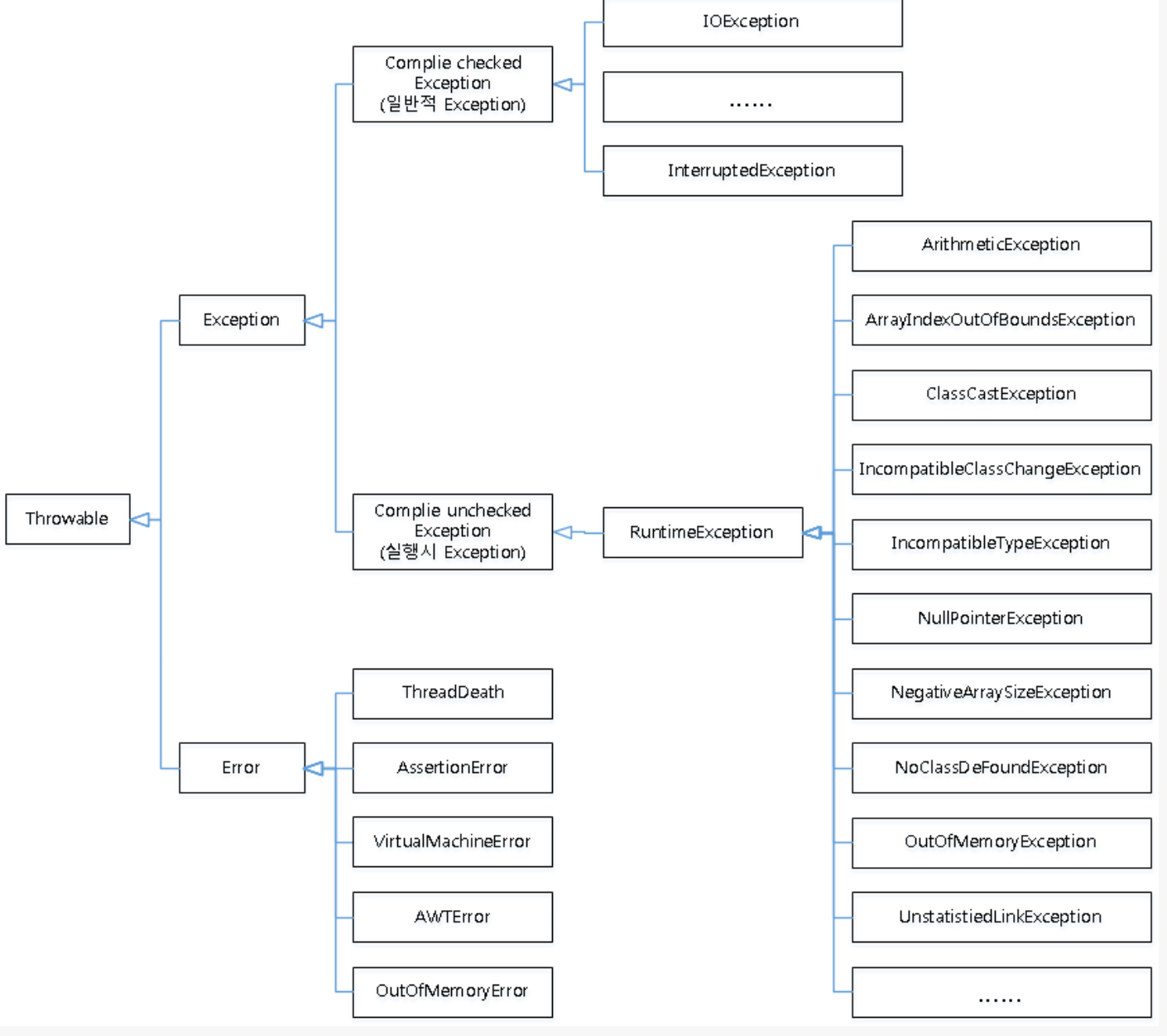
java.lang.Throwable 클래스, JAVA의 예외 종류 및 구조도, 자바프로그램의 예외 처리 과정
java.lang.Throwable · 자바에서 예외처리를 하기 위한 최상위 클래스 · Throwable 클래스를 상속받은 자식 클래스들을 예외처리에서 사용하게 됩니다. · Throwable 클래..
codedragon.tistory.com
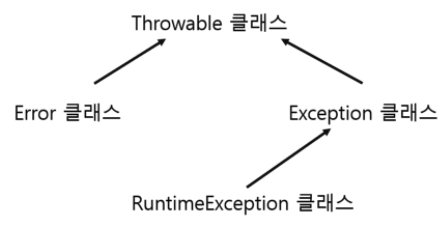
Throwable 클래스는
자바에서 예외를 처리하기 위한 최상위 클래스
Throwable 클래스를 상속받은 자식들을 예외처리에서 사용하게 된다.
* The {@code Throwable} class is the superclass of all errors and
* exceptions in the Java language. Only objects that are instances of this
* class (or one of its subclasses) are thrown by the Java Virtual Machine or
* can be thrown by the Java {@code throw} statement. Similarly, only
* this class or one of its subclasses can be the argument type in a
* {@code catch} clause.
Exception 클래스
try-catch를 통해 잡을 수 있는 상황에서 사용되는 클래스.
* The class {@code Exception} and its subclasses are a form of
* {@code Throwable} that indicates conditions that a reasonable
* application might want to catch.
*
* <p>The class {@code Exception} and any subclasses that are not also
* subclasses of {@link RuntimeException} are <em>checked
* exceptions</em>. Checked exceptions need to be declared in a
* method or constructor's {@code throws} clause if they can be thrown
* by the execution of the method or constructor and propagate outside
* the method or constructor boundary.
*
Error 클래스
Thorwable의 서브 클래스이고, try나 catch로 잡으면 안되는 심각한 문제에 대비하여 사용함.
* An {@code Error} is a subclass of {@code Throwable}
* that indicates serious problems that a reasonable application
* should not try to catch. Most such errors are abnormal conditions.
* The {@code ThreadDeath} error, though a "normal" condition,
* is also a subclass of {@code Error} because most applications
* should not try to catch it.
* <p>
* A method is not required to declare in its {@code throws}
* clause any subclasses of {@code Error} that might be thrown
* during the execution of the method but not caught, since these
* errors are abnormal conditions that should never occur.
*
* That is, {@code Error} and its subclasses are regarded as unchecked
* exceptions for the purposes of compile-time checking of exceptions.
*
RuntimeException
* {@code RuntimeException} is the superclass of those
* exceptions that can be thrown during the normal operation of the
* Java Virtual Machine.
*
* <p>{@code RuntimeException} and its subclasses are <em>unchecked
* exceptions</em>. Unchecked exceptions do <em>not</em> need to be
* declared in a method or constructor's {@code throws} clause if they
* can be thrown by the execution of the method or constructor and
* propagate outside the method or constructor boundary.
*
package java.net에 선언된 클래스. 데이터를 보내는 쪽에서 객체를 생성하여 사용한다.
데이터를 보내는 쪽에서 많이 사용하고. 원격에 있는 장비와의 연결 상태를 보관하기 위한 클래스
javadocs에는 아래와 같이 기술되어 있다.
"소켓은 두개의 machine의 연결을 위한 endpoint이다."
실제 동작은 SocketImpl의 instance에 의해 동작한다.
데이터를 보내기 위한 클래스이고, 데이터를 받는 서버에서는 클라에서 접속을 하면 Socket 객체를 생성하지만, 데이터를 보내는 쪽에서는 직접 생성해야 한다.
* This class implements client sockets (also called just
* "sockets"). A socket is an endpoint for communication
* between two machines.
* <p>
* The actual work of the socket is performed by an instance of the
* {@code SocketImpl} class. An application, by changing
* the socket factory that creates the socket implementation,
* can configure itself to create sockets appropriate to the local
* firewall.
ServerSocket 클래스
1.0에서 소개됨. 네트워크 상의 응답을 기다린다. 실제 동작은 SockeImpl의 인스턴스에 의해 동작한다.
애플리케이션은 소켓 팩토리를 통해 , local의 방화벽에 맞게 소켓 구현을 설정할 수 있다.
public class ServerSocket implements java.io.Closeable {
}
* This class implements server sockets. A server socket waits for
* requests to come in over the network. It performs some operation
* based on that request, and then possibly returns a result to the requester.
* <p>
* The actual work of the server socket is performed by an instance
* of the {@code SocketImpl} class. An application can
* change the socket factory that creates the socket
* implementation to configure itself to create sockets
* appropriate to the local firewall.그리고 bindAddr을 통해서, 특정 주소에서만 접근이 가능하도록 지정할 때 사용함.
* Create a server with the specified port, listen backlog, and
* local IP address to bind to. The <i>bindAddr</i> argument
* can be used on a multi-homed host for a ServerSocket that
* will only accept connect requests to one of its addresses.accept() 객체 생성후 사용자의 요청을 대기하는 메소드 SocketImpl에 구현되어 있다.
/**
* Accepts a connection.
*
* @param s the accepted connection.
* @throws IOException if an I/O error occurs when accepting the
* connection.
*/
protected abstract void accept(SocketImpl s) throws IOException;
close() 소켓 연결을 종료하는 메소드
public interface AutoCloseable {
void close() throws Exception;
} /**
* Closes this socket.
*
* @throws IOException if an I/O error occurs when closing this socket.
*/
protected abstract void close() throws IOException;
위 close는 Closeable 인터페이스에 구현되어 있다.
그리고 AutoCloseable 클래스는 아래와 같다.
1.7에서 소개되었고,
* An object that may hold resources (such as file or socket handles)
* until it is closed. The {@link #close()} method of an {@code AutoCloseable}
* object is called automatically when exiting a {@code
* try}-with-resources block for which the object has been declared in
* the resource specification header. This construction ensures prompt
* release, avoiding resource exhaustion exceptions and errors that
* may otherwise occur.
public interface Closeable extends AutoCloseable {
public void close() throws IOException;
}
Exception의 서브 클래스. UncheckedException은 이 클래스를 통해서 잡아야 한다.
더 알아보기
+ 자바7에서는 or을 의미하는 파이프로 연결하여 간단하게 처리할 수 있다.
try{
}catch(IllegalArgumentException | FileNotFoundException){
}
그리고 AutoCloseable이라는 인터페이스가 추가되어, try-with-resource를 사용할 때에는 이 인터페이스를 구현한 클래스는 별도로 close()를 호출해줄 필요가 없다. 즉 finally 문장에서 close()를 처리하기 위해서 코드의 가독성을 떨어뜨릴 필요가 없다.
즉 AutoCloseable을 구현한 객체는 Fainlly 문장안에서 별도로 처리할 필요가 없다.
TCP와는 다르게 클래스 하나에서 보내는 역할과 받는 역할을 모두 수행할 수 있다.
스트림을 사용하지 않고 DatagarmPacket이라는 클래스를 사용함
javadocs에는 아래와 같이 기술되어 있다.
datagram packet를 나타내는 클래스이다.
Datagarm 패킷은 비연결성 packet 전송 service에 쓰인다.
각각의 message는
여러개의 packets은 한 machine에서 다른 machine으로 전송된다.
순서가 보장되지 않고, 전송이 보장되지 않는다.
* This class represents a datagram packet.
* <p>
* Datagram packets are used to implement a connectionless packet
* delivery service. Each message is routed from one machine to
* another based solely on information contained within that packet.
* Multiple packets sent from one machine to another might be routed
* differently, and might arrive in any order. Packet delivery is
* not guaranteed.
*
* <p>
* Unless otherwise specified, passing a {@code null} argument causes
* a {@link NullPointerException NullPointerException} to be thrown.
*
* <p>
* Methods and constructors of {@code DatagramPacket} accept parameters
* of type {@link SocketAddress}. {@code DatagramPacket} supports
* {@link InetSocketAddress}, and may support additional {@code SocketAddress}
* sub-types.
final 클래스이고 더이상 확장할 수 없게 선언되어 있다.
public final
class DatagramPacket다음과 같은 생성자가 있다.
public DatagramPacket(byte buf[], int offset, int length) {
setData(buf, offset, length);
}
public DatagramPacket(byte buf[], int length) {
this (buf, 0, length);
}
public DatagramPacket(byte buf[], int offset, int length,
InetAddress address, int port) {
setData(buf, offset, length);
setAddress(address);
setPort(port);
}
public DatagramPacket(byte buf[], int offset, int length, SocketAddress address) {
setData(buf, offset, length);
setSocketAddress(address);
}
public DatagramPacket(byte buf[], int length,
InetAddress address, int port) {
this(buf, 0, length, address, port);
}
public DatagramPacket(byte buf[], int length, SocketAddress address) {
this(buf, 0, length, address);
}
여기서 byte 배열은 전송되는 데이터이다. 그리고 offset은 전송되는 byte배열의 첫 위치이다 offset이 1이면 1번째부터 데이터를 전송한다,
length는 데이터의 크기를 의미하는데, 이 값이 byte 배열의 크기보다 작으면 java.lang.IllegalArgumentException이 발생한다.
주요 메소드
getData()
/**
* Returns the data buffer. The data received or the data to be sent
* starts from the {@code offset} in the buffer,
* and runs for {@code length} long.
*
* @return the buffer used to receive or send data
* @see #setData(byte[], int, int)
*/
public synchronized byte[] getData() {
return buf;
}byte[]로 전송받은 데이터를 리턴하고 스레드세이프하다.
getLength()
전송받은 데이터의 길이를 int 타입으로 리턴함.
/**
* Returns the length of the data to be sent or the length of the
* data received.
*
* @return the length of the data to be sent or the length of the
* data received.
* @see #setLength(int)
*/
public synchronized int getLength() {
return length;
}
DataSocket
아래와 같이 정의되어 있고
public class DatagramSocket implements java.io.Closeablejavadocs에는 아래와 같이 기술되어 있다.
"Datagram Socket은 packet을 보내거나 받기위한 전송 service의 point이다.
datagram socket에 의해 송수신 되는 packet은 각각 주소가 다르고 다르게 route된다.
여러 packet들은 한 machine에서 다른 machine으로 routed되고, 각기 다른 순서로 도착한다."
* This class represents a socket for sending and receiving datagram packets.
*
* <p>A datagram socket is the sending or receiving point for a packet
* delivery service. Each packet sent or received on a datagram socket
* is individually addressed and routed. Multiple packets sent from
* one machine to another may be routed differently, and may arrive in
* any order.
*
* <p> Where possible, a newly constructed {@code DatagramSocket} has the
* {@link StandardSocketOptions#SO_BROADCAST SO_BROADCAST} socket option enabled so as
* to allow the transmission of broadcast datagrams. In order to receive
* broadcast packets a DatagramSocket should be bound to the wildcard address.
* In some implementations, broadcast packets may also be received when
* a DatagramSocket is bound to a more specific address.비 구체화 타입(non-reifiable type) : 타입 소거자에 의해 컴파일 타임에 타입 정보가 사라지는 것(런타임에 구체화하지 않는 것)
구체화 타입(reifiable type) : 자신의 타입 정보를 런타임 시에 알고 지키게 하는 것 (런타임에 구체화하는 것). 런타임 시에 완전하게 오브젝트 정보를 표현할 수 있는 타입
제너릭 타입 소거 : 원소 타입을 컴파일 타임에만 검사하고 런타임에는 해당 타입 정보를 알 수 없는 것. 다른 말로는 컴파일 타임에만 제약 조건을 적용하고, 런타임에 타입에 대한 정보를 소거하는 프로세스.
- Primitives, non-generic types, raw types 등이 있다.
non-reifiable 문제는 자바에서 제네릭을 사용하지 않는 버전과의 호환성을 위해서 제공했던 기능 때문에 발생.
하위호환성을 위해 객체의 타입 정보를 컴파일 시에 확인하여 동일한 동작을 보장하여 Runtime 전에 소거함.
아래는 컴파일 이전과 이후의 코드이다. List<String>는 ArrayList로 변경되면서 타입 정보가 사라진 것을 확인할 수 있다.
Object[] 배열은 Long[] 배열 형태의 실제 타입으로 변경된 것을 확인할 수 있다.
// before
public static void main(String... args) {
List<String> list = new ArrayList<>();
list.add("Hi");
Object[] array = new Long[10];
array[0] = 1L;
}
// after
public static void main(String... var0) {
ArrayList var1 = new ArrayList();
var1.add("Hi");
Long[] var2 = new Long[10];
var2[0] = Long.valueOf(1L);
}
예시:
첫번째 매개변수에는 추가된느 데이터가 저장되는 Collection을 구현한 클래스의 객체
두번째 매개변수에는 추가되는 객체들이 나열되도록 되어 있음
public static <T> boolean addAll(Collection<? super T>c, T... elements )
public void addData() {
ArrayList<ArrayList<String>> list = new ArrayList(); // ArrayList내에 ArrayList<String>이 저장되는 list라는 객체 추가
ArrayList<String> newDataList<new ArrayLIst<>; // newDataListㅇ라는 객체를 생성하고, 값을 하나 추가
newDataList.add("a"); // Collections의 addAll() 메소드를 사용하여 list에 newDataList라는 객체를 저장하도록 했음.
Java6에서 컴파일 하면 unchecked generic array creation of tpye .. 이라는 경고가 발생함.
가변 매개변수를 사용하면
public static <T> boolean addAll(Collection<? super T> c, T... elements)
가변매개변수를 사용할 경우에 실제로 내부적으로는 다음과 같은 Object의 배열로 처리됨.
public static boolean addAll(java.util.Collection c, java.lang.Object[] elements);
이렇게 배열로 처리되면, 잠재적으로 문제가 발생할 수 있다.
이 경고를 없애려면 @SafeVarags라는 어노테이션을 메소드 선언부에 추가하면 된다.
https://medium.com/@joongwon/java-java%EC%9D%98-generics-604b562530b3
비 구체화 타입(non-reifiable type) : 타입 소거자에 의해 컴파일 타임에 타입 정보가 사라지는 것(런타임에 구체화하지 않는 것)
구체화 타입(reifiable type) : 자신의 타입 정보를 런타임 시에 알고 지키게 하는 것 (런타임에 구체화하는 것). 런타임 시에 완전하게 오브젝트 정보를 표현할 수 있는 타입
제너릭 타입 소거 : 원소 타입을 컴파일 타임에만 검사하고 런타임에는 해당 타입 정보를 알 수 없는 것. 다른 말로는 컴파일 타임에만 제약 조건을 적용하고, 런타임에 타입에 대한 정보를 소거하는 프로세스.
- Primitives, non-generic types, raw types 등이 있다.
non-reifiable 문제는 자바에서 제네릭을 사용하지 않는 버전과의 호환성을 위해서 제공했던 기능 때문에 발생.
하위호환성을 위해 객체의 타입 정보를 컴파일 시에 확인하여 동일한 동작을 보장하여 Runtime 전에 소거함.
아래는 컴파일 이전과 이후의 코드이다. List<String>는 ArrayList로 변경되면서 타입 정보가 사라진 것을 확인할 수 있다.
Object[] 배열은 Long[] 배열 형태의 실제 타입으로 변경된 것을 확인할 수 있다.
// before
public static void main(String... args) {
List<String> list = new ArrayList<>();
list.add("Hi");
Object[] array = new Long[10];
array[0] = 1L;
}
// after
public static void main(String... var0) {
ArrayList var1 = new ArrayList();
var1.add("Hi");
Long[] var2 = new Long[10];
var2[0] = Long.valueOf(1L);
}
예시:
첫번째 매개변수에는 추가된느 데이터가 저장되는 Collection을 구현한 클래스의 객체
두번째 매개변수에는 추가되는 객체들이 나열되도록 되어 있음
public static <T> boolean addAll(Collection<? super T>c, T... elements )
public void addData() {
ArrayList<ArrayList<String>> list = new ArrayList(); // ArrayList내에 ArrayList<String>이 저장되는 list라는 객체 추가
ArrayList<String> newDataList<new ArrayLIst<>; // newDataListㅇ라는 객체를 생성하고, 값을 하나 추가
newDataList.add("a"); // Collections의 addAll() 메소드를 사용하여 list에 newDataList라는 객체를 저장하도록 했음.
Java6에서 컴파일 하면 unchecked generic array creation of tpye .. 이라는 경고가 발생함.
가변 매개변수를 사용하면
public static <T> boolean addAll(Collection<? super T> c, T... elements)
가변매개변수를 사용할 경우에 실제로 내부적으로는 다음과 같은 Object의 배열로 처리됨.
public static boolean addAll(java.util.Collection c, java.lang.Object[] elements);
이렇게 배열로 처리되면, 잠재적으로 문제가 발생할 수 있다.
이 경고를 없애려면 @SafeVarags라는 어노테이션을 메소드 선언부에 추가하면 된다.
https://medium.com/@joongwon/java-java%EC%9D%98-generics-604b562530b3
JVM의 Heap메모리의 Permenent 영역에 존재한다.
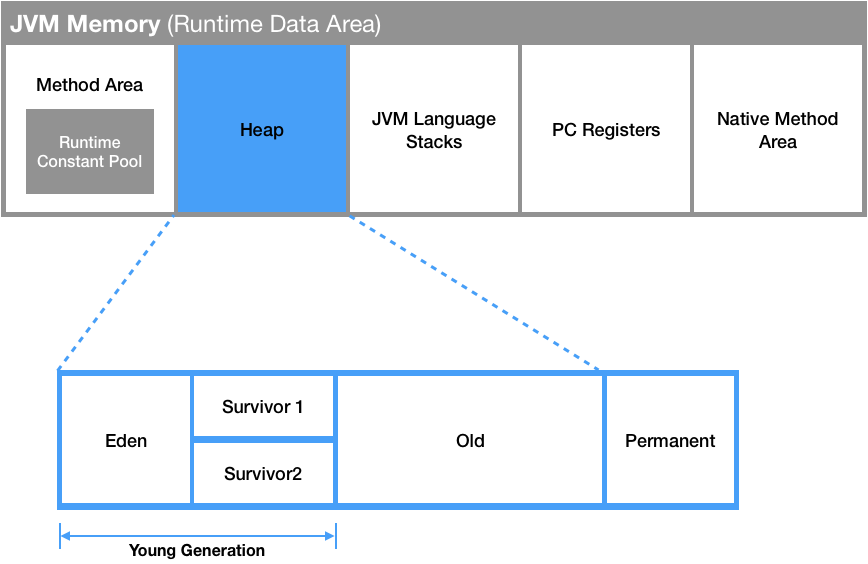
자바 7에서의 힙에서는
- PerGen에 있는 클래스의 인스턴스 저장
- -Xms(min), -Xmx(max로 사이즈 조정
PermGen
- 클래스와 메소드의 메타데이터 저장
- 상수풀 정보
- JVM, JIT 관련 데이터
- -XX:PermSize(min), -XX:MaxPermSize(max)로 사이즈 조정
Perm 영역은 보통 Class의 Meta 정보나, 메소드의 메타 정보, 스태틱 변수와 상수 정보들이 저장되는 공간으로 흔히 메타데이터 저장 영역이라고도 한다.
하지만 자바 8에서는 Native 영역으로 이동하여 Metaspace 영역으로 변경되었다.
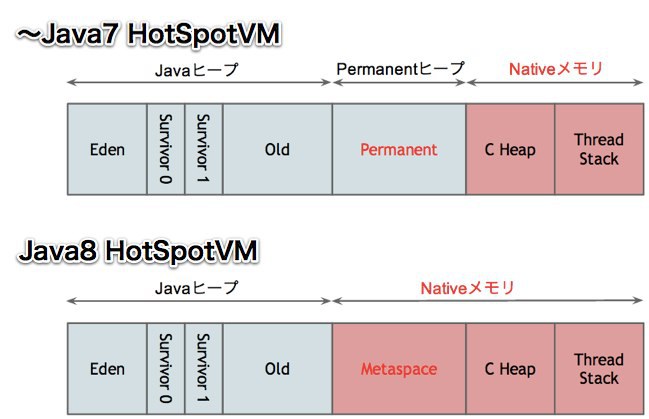
자바8 : 메타스페이스 영역
자바 8에부터는 자바 7의 Perm 영역이 삭제되고 Native 영역으로 이동해서 MetaSpace 영역으로 변경됨.
다만 기존 Perm에 존재하는 Static Object는 Heap 영역으로 옮겨져 GC의 대상이 될 수 있도록 변경됨.
Perm은 JVM에 의해 크기가 강제되던 영역임.
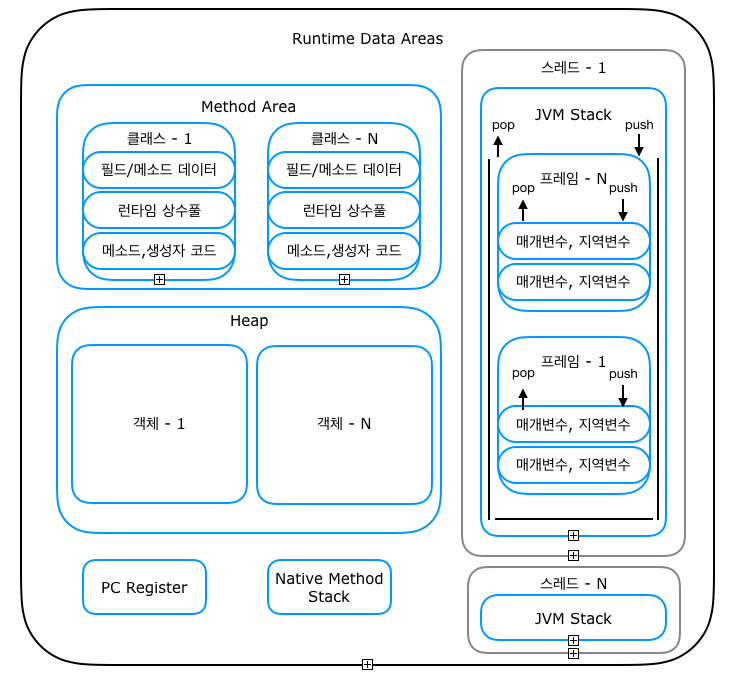
왜 Perm이 삭제되고, Metaspace 영역이 추가된 것일까?
Metaspace 영역은 Heap이 아닌, Native 메모리 영역으로 취급하게 된다.
OS 레벨에서 자동으로 관리하게 됨
옵션을 통해 Metaspace의 크기를 줄일 수 도 있음
Metaspace가 Native 영역을 이용함으로 영역 확보의 상한을 크게 의식할 필요가 줄어듦
Perm 영역크기로 인해 발생하는 OOM의 빈도가 줄어드는 효과
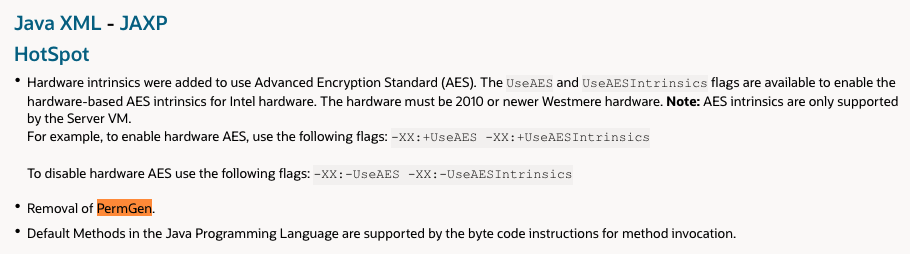
| Java7 | Java8 | |
| Class 메타데이터 | 저장 | 저장 |
| Method 메타 데이터 | 저장 | 저장 |
| Static Object 변수, 상수 | 저장 | Heap 영역으로 이동 |
| 메모리 튜닝 | Heap, Perm 영역 튜닝 | Heap 튜닝, Native는 OS가 동적 조정 |
| 메모리 옵션 | -XX:PermSize -XX:MaxPermSize |
-XX:MetaspaceSize -Xx:MaxMetaspaceSize |
JEP 122에서는 아래와 같이 기술하고 있다.
현재 Hotspot의 클래스 메타 데이터, interned String, class static 변수들은 Java heap의 permanent generation에 저장됩니다. permanent generation은 Hotspot이 관리하며, 앞에서 말한 것들을 모두 저장하므로 반드시 충분한 공간을 갖고 있어야 합니다. 클래스 메타 데이터와 static 변수들은 클래스가 로드될 때 permanent generation에 할당되고, 클래스가 언로드될 때 gc 처리됩니다. interned String은 permanent generation의 gc가 발생할 때 같이 수집됩니다.
구현 제안서에 따르면 클래스 메타 데이터는 네이티브 메모리에 할당하고, interned String와 클래스 statics는 Java heap으로 이동합니다. Hotspot은 클래스 메타 데이터에 대한 네이티브 메모리를 명시적으로 할당하고 해제할 것입니다. 새 클래스 메타 데이터의 할당은 네이티브 메모리의 사용 가능한 양에 의해 제한되며, 커맨드 라인을 통해 설정된 -XX:MaxPermSize 값으로 고정되지 않습니다.
네이티브 메모리에서의 클래스 메타 데이터 할당은, 여러 클래스 메타 데이터가 잘 들어가도록 충분한 크기의 여러 블록을 만들어 작업합니다. 각 블록은 클래스 로더와 연결되며 해당 클래스 로더가 로드한 모든 클래스 메타 데이터는 해당 클래스 로더의 블록에서 Hotspot에 의해 할당됩니다. 필요에 따라 클래스 로더에 추가 블록이 할당되기도 합니다. 블록 크기는 애플리케이션의 동작에 따라 다릅니다. 블록의 사이즈는 내부 및 외부 조각화(fragmentation)를 제한하기 위해 선택됩니다. 클래스 로더가 죽을 때 클래스 로더와 연관된 모든 블록을 해제하여 클래스 메타 데이터에 대한 공간을 확보합니다. 클래스 메타 데이터는 클래스의 수명 동안 이동하지 않습니다.
더 알아보기
Runtime Constant Pool
클래스 파일 constant_pool 테이블에 해당하는 영역
클래스와 인터페이스 상수, 메소드와 필드에 대한 모든 레퍼런스를 저장한다.
JVM은 런타임 상수 풀을 통해 해당 메소드나 필드의 실제 메모리 상 주소를 찾아 참조한다.
출처 :
https://johngrib.github.io/wiki/java8-why-permgen-removed/
JDK 8에서 Perm 영역은 왜 삭제됐을까
johngrib.github.io
volatile = 휘발성
그 변수를 휘발성 메모리에 만들어라 라는 뜻이다.
변수를 메인 메모리에 저장하겠다고 명시하는 것이다.
매번 변수의 값을 Read,Wrtie할 때마다 CPU cache에 저장된 값이 아닌 Main Memory에서 읽는 것이다 .
CPU Cache보다 Main Memory 비용이 더 크기 때문에 변수 값 일치를 보장해야만 하는 경우에만 volatile을 사용하는게 좋다.
Main Memory에 read, write 하는 작업의 원자성을 보장하는 경우.
원자성이 보장되는 경우에 volatile 키워드 만으로 안전하게 데이터를 교환할 수 있음.
멀티 스레드 환경에서 하나의 스레드만 read & write 하고 나머지 Thread가 read하는 상황에서 가장 최신의 값을 보장함
volatile은 왜 하나의 스레드가 write 하고 다른 스레드들은 read 하는 상황에서 적합하고.
여러개의 스레드가 write 하는상황에서 왜 적합하지 않을까?
volatile은 어떻게 원자성을 보장할까
오직 한 스레드에서만 읽을 수 있고 쓸 수 있는 변수를 생성할 수 있도록 함.
javadoc에는 아래와 같이 기술되어 있다.
* This class provides thread-local variables. These variables differ from
* their normal counterparts in that each thread that accesses one (via its
* {@code get} or {@code set} method) has its own, independently initialized
* copy of the variable. {@code ThreadLocal} instances are typically private
* static fields in classes that wish to associate state with a thread (e.g.,
* a user ID or Transaction ID). * <p>For example, the class below generates unique identifiers local to each
* thread.
* A thread's id is assigned the first time it invokes {@code ThreadId.get()}
* and remains unchanged on subsequent calls. * <p>Each thread holds an implicit reference to its copy of a thread-local
* variable as long as the thread is alive and the {@code ThreadLocal}
* instance is accessible; after a thread goes away, all of its copies of
* thread-local instances are subject to garbage collection (unless other
* references to these copies exist).
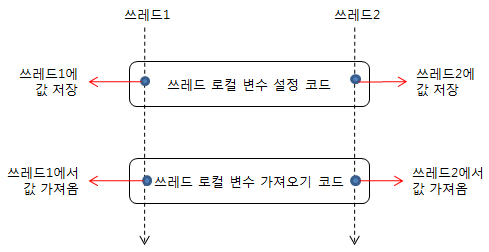
ThreadLocal의 기본 사용법
- ThreadLocal 객체를 생성한다.
- ThreadLocal.set() 메서드를 이용해서 현재 쓰레드의 로컬 변수에 값을 저장한다.
- ThreadLocal.get() 메서드를 이용해서 현재 쓰레드의 로컬 변수 값을 읽어온다.
- ThreadLocal.remove() 메서드를 이용해서 현재 쓰레드의 로컬 변수 값을 삭제한다.
ThreadLocal의 활용
ThreadLocal은 한 쓰레드에서 실행되는 코드가 동일한 객체를 사용할 수 있도록 해 주기 때문에 쓰레드와 관련된 코드에서 파라미터를 사용하지 않고 객체를 전파하기 위한 용도로 주로 사용되며, 주요 용도는 다음과 같다.
- 사용자 인증정보 전파 - Spring Security에서는 ThreadLocal을 이용해서 사용자 인증 정보를 전파한다.
- 트랜잭션 컨텍스트 전파 - 트랜잭션 매니저는 트랜잭션 컨텍스트를 전파하는 데 ThreadLocal을 사용한다.
- 쓰레드에 안전해야 하는 데이터 보관
이 외에도 쓰레드 기준으로 동작해야 하는 기능을 구현할 때 ThreadLocal을 유용하게 사용할 수 있다.
ThreadLocal 사용시 주의 사항
쓰레드 풀 환경에서 ThreadLocal을 사용하는 경우 ThreadLocal 변수에 보관된 데이터의 사용이 끝나면 반드시 해당 데이터를 삭제해 주어야 한다. 그렇지 않을 경우 재사용되는 쓰레드가 올바르지 않은 데이터를 참조할 수 있다.
https://javacan.tistory.com/entry/ThreadLocalUsage
https://velog.io/@skygl/ThreadLocal
NIO와 이름은 비슷하지만 크게 관련은 없는 NIO2가 7버전 부터 제공된다.
지금까지 파일을 다루기 위해서 제공한 io 패키지와 File 클래으세 미흡한 부분이 많았다. 그래서 이를 보완하는 내용이 많이 포함되어 있다.
파일의 속성을 다룰 수 있고, 심볼릭 링크까지 다룰 수 있는 기능 제공하고, 어떤 파일이 변경되었는지 쉽게 확인할 수 있는 WatchService 라는 클래스도 제공된다. 그리고 며가지 채널들도 추가됨.
File의 변경점
기존의 단점
- 심볼릭 링크, 속성, 파일의 원한 등에 대한 기능이 없음
- 파일을 삭제하는 delete() 메소드는 실패시 아무런 예외를 발생시키지 않고, boolean 타입의 결과만 제공해줌
- 파일이 변경되었는지 확인하는 방법은 lastModified()라는 메소드를 제공해주는 long 타입의 겨로가로 이전시간과 비교하는 수 밖에 없었는데, 이 메소드가 호출되면 연계되어 호출되는 클래스가 다수 존재하여 성능상 문제도 많음.
File 클래스를 대체하는 클래스
- Paths : 이 클래스가 제공하는 static한 get() 메소드를 사용하면 Path 라는 인터페이스의 객체를 얻을 수 있다. 여기서 파일과 경로에 대한 정보를 가지고 있음
- Files : 기존 File 클래스의 단점 보완, Path 객체를 사용하여 파일을 통제하는데 사용
- FileSystem : 현재 사용중인 파일 시스템에 대한 정보를 처리하는데 필요한 메소드를 제공함. getDefault()를 통해 현재 사용중인 기본 파일 시스템에 대한 정보를 갖고 있는 FileSystem 인터페이스의 객체를 얻을 수 있다
- FileStore : 파일을 저장하는 디바이스, 파티션, 볼륨 등에 대한 정보들을 확인하는데 필요한 메소드를 제공
위의 모든 클래스는 nio.file 패키지에 위치함.
*심볼링 링크란?
*CharSequence
A {@code CharSequence} is a readable sequence of {@code char} values. This
* interface provides uniform, read-only access to many different kinds of
* {@code char} sequences.
* A {@code char} value represents a character in the <i>Basic
* Multilingual Plane (BMP)</i> or a surrogate. Refer to <a
* href="Character.html#unicode">Unicode Character Representation</a> for details.Files 클래스
쓰기, 읽기, 복사,이동, 삭제 등의 메소드들을 제공
- StandardOpenOption : 파일들을 열 때 조건을 의미함. Enum 클래스임
- APPEND : 쓰기 권한으로 파일을 열고, 기존에 존재하는 데이터가 있으면 가장 끝부분부터 데이터를 저장할 때
- CREATE : 파일이 존재하지 않으면 새로 생성
- CREATE_NEW : 파일을 생성하여, 기존 파일이 있으면 실패로 간주
- DELETE_ON_CLOSE : 파일을 닫을 때 삭제함
- DSYNC : 수정하는 모든 작업이 순차적으로 처리되도록
- READ : 읽기 권한으로 열 때
- SPARSE : 파일을 Sparse할 때 사용
- SYNC : 메타데이터에 대한 모든 업데이트는 순차적으로 파일 저장소에서 처리되도록 할 때
- TUNCATE_EXISTING : 이미 존재하는 파일이 있을 때, 쓰기 ㅇ권한으로 파일을 열고, 해당 파일의 모든 내용을 지울 때 사용
- WRITE : 쓰기 권한으로 파일 열 때
- StandardCopyOption
- ATOMIC_MOVE : 시스템 처리를 통하여 단일 파일을 이동, 복사할 때에는 사용 불가
- COPY_ATTRIBUTES : 새로운 파일에 속성 정보도 복사
- REPLACE_EXISITING : 기존 파일이 있으면 새 파일로 변경
File클래스에서 제공하는 기능보다 많은 기능을 제공함
/**
* This class consists exclusively of static methods that operate on files,
* directories, or other types of files.
*
* <p> In most cases, the methods defined here will delegate to the associated
* file system provider to perform the file operations.
*
* @since 1.7
*/
Path 인터페이스
public interface Path
extends Comparable<Path>, Iterable<Path>, Watchable정의된 함수
1. relativize()
* Constructs a relative path between this path and a given path.
2. toAbsolutePath()
* Returns a {@code Path} object representing the absolute path of this
* path.
3. normalize()
* Returns a path that is this path with redundant name elements eliminated.
(경로상 . 혹은 .. 을 없애는 작업)
4. resolve()
* Resolve the given path against this path.
(주어진 문자열 하나를 경로로 생각하고, 현재 Path의 가장 마지막 Path로 추가)
WatchService
파일이 변경되었는지 확인하는 클래스
기존에는 lastModified()를 주기적으로 호출해야하는 불편함이 있었음.
아래와 같이 선언되어 있음.
public interface WatchService extends Closeable
구현 메서드 목록
@Override
void close() throws IOException;
WatchKey poll();
WatchKey poll(long timeout, TimeUnit unit)
throws InterruptedException; WatchKey take() throws InterruptedException;
* A watch service that <em>watches</em> registered objects for changes and
* events. For example a file manager may use a watch service to monitor a
* directory for changes so that it can update its display of the list of files
* when files are created or deleted.
SeekableByteChannel(random access)
채널 : 디바이스 파일 네트워크 등과의 연결 상태를 나타내는 클래스
바이트 기반의 채널을 처리하는 데 사용. 현재 위치를관리하고 해당 위치가 변경되는 것을 허용하도록 되어 있다. 채널을 보다 유연하게 처리하는데 사용된다.
public interface SeekableByteChannel
extends ByteChannel * A byte channel that maintains a current <i>position</i> and allows the
* position to be changed.
*
* <p> A seekable byte channel is connected to an entity, typically a file,
* that contains a variable-length sequence of bytes that can be read and
* written. The current position can be {@link #position() <i>queried</i>} and
* {@link #position(long) <i>modified</i>}. The channel also provides access to
* the current <i>size</i> of the entity to which the channel is connected. The
* size increases when bytes are written beyond its current size; the size
* decreases when it is {@link #truncate <i>truncated</i>}.
*
NetworkChannel,
네트워크 소켓을 처리하기 위한 채널, 네트워크 연결에 대한 바인딩, 소켓 옵션을 세팅하고, 로컬 주소를 알려주는 인터페이스
package java.nio.channels;
* A channel to a network socket.
*
* <p> A channel that implements this interface is a channel to a network
* socket. The {@link #bind(SocketAddress) bind} method is used to bind the
* socket to a local {@link SocketAddress address}, the {@link #getLocalAddress()
* getLocalAddress} method returns the address that the socket is bound to, and
* the {@link #setOption(SocketOption,Object) setOption} and {@link
* #getOption(SocketOption) getOption} methods are used to set and query socket
* options. An implementation of this interface should specify the socket options
* that it supports.public interface NetworkChannel
extends Channel
MulticastChannel
IP 멀티캐스트를 지원하는 네트워크 채널, 여기서 멀티 태스크는 네트워크 주소인 IP를 그룹으로 묶고 그 그룹에 데이터를 전송하는 방식
* A network channel that supports Internet Protocol (IP) multicasting.
*
* <p> IP multicasting is the transmission of IP datagrams to members of
* a <em>group</em> that is zero or more hosts identified by a single destination
* address.public interface MulticastChannel
extends NetworkChannel
AsynchronousFileChannel
AsynchronousFileChannel을 처리한 결과는 java.util.concurrent 패키지의 Future 객체로 받게 된다.
Future 인터페이스로 결과를 받지 않으면
CompletionHandler 라는 인터페이스를 구현한 객체로 받을 수도 있다. CompletionHandler는 모든 데이터가 성공적으로 처리되었을 대 수행되는 completed 메소드와 실패했을 때 처리되는 failed() 메소드를 제공하므로 필요에 따라 적절한 구현체를 사용하면 된다.
* An asynchronous channel for reading, writing, and manipulating a file.
*
* <p> An asynchronous file channel is created when a file is opened by invoking
* one of the {@link #open open} methods defined by this class. The file contains
* a variable-length sequence of bytes that can be read and written and whose
* current size can be {@link #size() queried}. The size of the file increases
* when bytes are written beyond its current size; the size of the file decreases
* when it is {@link #truncate truncated}.
*public abstract class AsynchronousFileChannel
implements AsynchronousChannelFuture
비동기 연산의 결과를나타내는 인터페이스.
* A {@code Future} represents the result of an asynchronous
* computation. Methods are provided to check if the computation is
* complete, to wait for its completion, and to retrieve the result of
* the computation. The result can only be retrieved using method
* {@code get} when the computation has completed, blocking if
* necessary until it is ready.아래와 같은 메서드들이 정의되어 있다.
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
TransferQueue
package java.util.concurrent;에 정의된 인터페이스
아래와 같이 정의되어 있음.
Producer/Consumer 패턴을 통해특정 타입의 객체를 처리하는 스레드 풀을 미리 만들어 놓고, 해당 풀이 객체들을 받으면 처리하도록 한다.
이 기능을 보다 일반화 하여 SynchronousQueue의 기능을 인터페이스로 끌어 올리면서 좀 더 일반화 해서 BlockingQueue를 확장한 것이다.
public interface TransferQueue<E> extends BlockingQueue<E> 아래와 같은 메서드들이 정의되어 있다.
boolean tryTransfer(E e);
void transfer(E e) throws InterruptedException;
boolean tryTransfer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
boolean hasWaitingConsumer();
int getWaitingConsumerCount();
Objects
java.util 패키지에 선언된 클래스
아래와 같이 정의되어 있고.
public final class Objects이 클래스는 compare(), equals(), hash(), hashCode(), toSTring() 등의 static한 메소드들을 제공한다. 매개변수로 넘어오는 객체가 null이라 할지라도 예외를 발생시키지 않도록 구현해 놓은 특징이 있다.
* This class consists of {@code static} utility methods for operating
* on objects, or checking certain conditions before operation. These utilities
* include {@code null}-safe or {@code null}-tolerant methods for computing the
* hash code of an object, returning a string for an object, comparing two
* objects, and checking if indexes or sub-range values are out of bounds.
*
구현부를 보면
아래와 같이 null을 추가적으로 체크해주는 것을 확인할 수 있다.
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
} public static int hashCode(Object o) {
return o != null ? o.hashCode() : 0;
}
java.util에 속하고, 1.8부터 제공됨. Null 처리를 간편하게 하기 위해서 등장.
T 객체를 포장해주는 래퍼 클래스이고, NullPointerException 예외를 예방할 수 있다.
public final class Optional<T>final 로 정의되어 있어 더 이상 확장이 불가능하다.
Optional의 특이한 점은
아래와 같이 객체를 생성하지 않는다.
new Optional();
아래의 3개의 메소드를 통해 Optional 클래스의 객체를 생성할 수 있다.
데이터가 없는 Optional 객체를 생성하려면 이와 같이 empty() 메소드를 이용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an empty {@code Optional} instance. No value is present for this
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
만약 null이 추가될 수 있는 상황이면 이 메소드를 사용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an {@code Optional} describing the given value, if
* non-{@code null}, otherwise returns an empty {@code Optional}.
* public static <T> Optional<T> ofNullable(T value) {
return value == null ? (Optional<T>) EMPTY
: new Optional<>(value);
}
반드시 데이터가 들어갈 수 있는 상황에는 of() 메소드를 사용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an {@code Optional} describing the given non-{@code null}
* value.
public static <T> Optional<T> of(T value) {
return new Optional<>(Objects.requireNonNull(value));
}
아래의 메소드는 데이터를 리턴하는 메소드들이다.
가장 많이 사용되는메소드이다. 만약 데이터가 없을 경우에는 null이 리턴된다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise throws
* {@code NoSuchElementException}.
*
* @apiNote
* The preferred alternative to this method is {@link #orElseThrow()}.
*
* @return the non-{@code null} value described by this {@code Optional}
* @throws NoSuchElementException if no value is present public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
만약 값이 없을 경우에는 orElse() 메소드를 사용하여 기본값을 지정할 수 있다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise returns
* {@code other}.
*
* @param other the value to be returned, if no value is present.
* May be {@code null}.
* @return the value, if present, otherwise {@code other}
*/ public T orElse(T other) {
return value != null ? value : other;
}
Supplier<T>라는 인터페이스를 활용하는 방법으로 orElseGet()을 사용할 수 있다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise returns the result
* produced by the supplying function.
*
* @param supplier the supplying function that produces a value to be returned
* @return the value, if present, otherwise the result produced by the
* supplying function
* @throws NullPointerException if no value is present and the supplying
* function is {@code null}
*/ public T orElseGet(Supplier<? extends T> supplier) {
return value != null ? value : supplier.get();
}
만약 여기에도 데이터가 없을 경우에 예외를 발생시키고 싶으면 orElseThrow() 메소드를 사용한다.
* If a value is present, returns the value, otherwise throws
* {@code NoSuchElementException}.
*
* @return the non-{@code null} value described by this {@code Optional}
* @throws NoSuchElementException if no value is present
* @since 10
*/
public T orElseThrow() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
java.util에 속하고, 1.8부터 제공됨. Null 처리를 간편하게 하기 위해서 등장.
T 객체를 포장해주는 래퍼 클래스이고, NullPointerException 예외를 예방할 수 있다.
public final class Optional<T>final 로 정의되어 있어 더 이상 확장이 불가능하다.
Optional의 특이한 점은
아래와 같이 객체를 생성하지 않는다.
new Optional();
아래의 3개의 메소드를 통해 Optional 클래스의 객체를 생성할 수 있다.
데이터가 없는 Optional 객체를 생성하려면 이와 같이 empty() 메소드를 이용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an empty {@code Optional} instance. No value is present for this
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
만약 null이 추가될 수 있는 상황이면 이 메소드를 사용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an {@code Optional} describing the given value, if
* non-{@code null}, otherwise returns an empty {@code Optional}.
* public static <T> Optional<T> ofNullable(T value) {
return value == null ? (Optional<T>) EMPTY
: new Optional<>(value);
}
반드시 데이터가 들어갈 수 있는 상황에는 of() 메소드를 사용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an {@code Optional} describing the given non-{@code null}
* value.
public static <T> Optional<T> of(T value) {
return new Optional<>(Objects.requireNonNull(value));
}
아래의 메소드는 데이터를 리턴하는 메소드들이다.
가장 많이 사용되는메소드이다. 만약 데이터가 없을 경우에는 null이 리턴된다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise throws
* {@code NoSuchElementException}.
*
* @apiNote
* The preferred alternative to this method is {@link #orElseThrow()}.
*
* @return the non-{@code null} value described by this {@code Optional}
* @throws NoSuchElementException if no value is present public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
만약 값이 없을 경우에는 orElse() 메소드를 사용하여 기본값을 지정할 수 있다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise returns
* {@code other}.
*
* @param other the value to be returned, if no value is present.
* May be {@code null}.
* @return the value, if present, otherwise {@code other}
*/ public T orElse(T other) {
return value != null ? value : other;
}
Supplier<T>라는 인터페이스를 활용하는 방법으로 orElseGet()을 사용할 수 있다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise returns the result
* produced by the supplying function.
*
* @param supplier the supplying function that produces a value to be returned
* @return the value, if present, otherwise the result produced by the
* supplying function
* @throws NullPointerException if no value is present and the supplying
* function is {@code null}
*/ public T orElseGet(Supplier<? extends T> supplier) {
return value != null ? value : supplier.get();
}
만약 여기에도 데이터가 없을 경우에 예외를 발생시키고 싶으면 orElseThrow() 메소드를 사용한다.
* If a value is present, returns the value, otherwise throws
* {@code NoSuchElementException}.
*
* @return the non-{@code null} value described by this {@code Optional}
* @throws NoSuchElementException if no value is present
* @since 10
*/
public T orElseThrow() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
java.util에 속하고, 1.8부터 제공됨. Null 처리를 간편하게 하기 위해서 등장.
T 객체를 포장해주는 래퍼 클래스이고, NullPointerException 예외를 예방할 수 있다.
public final class Optional<T>final 로 정의되어 있어 더 이상 확장이 불가능하다.
Optional의 특이한 점은
아래와 같이 객체를 생성하지 않는다.
new Optional();
아래의 3개의 메소드를 통해 Optional 클래스의 객체를 생성할 수 있다.
데이터가 없는 Optional 객체를 생성하려면 이와 같이 empty() 메소드를 이용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an empty {@code Optional} instance. No value is present for this
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
만약 null이 추가될 수 있는 상황이면 이 메소드를 사용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an {@code Optional} describing the given value, if
* non-{@code null}, otherwise returns an empty {@code Optional}.
* public static <T> Optional<T> ofNullable(T value) {
return value == null ? (Optional<T>) EMPTY
: new Optional<>(value);
}
반드시 데이터가 들어갈 수 있는 상황에는 of() 메소드를 사용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an {@code Optional} describing the given non-{@code null}
* value.
public static <T> Optional<T> of(T value) {
return new Optional<>(Objects.requireNonNull(value));
}
아래의 메소드는 데이터를 리턴하는 메소드들이다.
가장 많이 사용되는메소드이다. 만약 데이터가 없을 경우에는 null이 리턴된다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise throws
* {@code NoSuchElementException}.
*
* @apiNote
* The preferred alternative to this method is {@link #orElseThrow()}.
*
* @return the non-{@code null} value described by this {@code Optional}
* @throws NoSuchElementException if no value is present public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
만약 값이 없을 경우에는 orElse() 메소드를 사용하여 기본값을 지정할 수 있다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise returns
* {@code other}.
*
* @param other the value to be returned, if no value is present.
* May be {@code null}.
* @return the value, if present, otherwise {@code other}
*/ public T orElse(T other) {
return value != null ? value : other;
}
Supplier<T>라는 인터페이스를 활용하는 방법으로 orElseGet()을 사용할 수 있다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise returns the result
* produced by the supplying function.
*
* @param supplier the supplying function that produces a value to be returned
* @return the value, if present, otherwise the result produced by the
* supplying function
* @throws NullPointerException if no value is present and the supplying
* function is {@code null}
*/ public T orElseGet(Supplier<? extends T> supplier) {
return value != null ? value : supplier.get();
}
만약 여기에도 데이터가 없을 경우에 예외를 발생시키고 싶으면 orElseThrow() 메소드를 사용한다.
* If a value is present, returns the value, otherwise throws
* {@code NoSuchElementException}.
*
* @return the non-{@code null} value described by this {@code Optional}
* @throws NoSuchElementException if no value is present
* @since 10
*/
public T orElseThrow() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
Arrays 클래스에는 다음과 같은 static 메소드들이 있다.
public static int binarySearch // 배열 내에서의 검색
public static <T> T[] copyOf // 배열의 복제
public static boolean equals // 배열의 비교
public static void fill // 배열 채우기
public static int hashCode // 배열 해시코드 제공
public static void sort // 정렬
public static String toString // 배열 내용을 출력
javadocs에는 아래와 같이 기술되어 있다.
의역해보면, 다양한 arrays 연산을 위한 메서드들을 포함하고 있다.
lists처럼 다루기 위한 static factory를 포함하고 있다.
이 메서드는
This class contains various methods for manipulating arrays (such as
* sorting and searching). This class also contains a static factory
* that allows arrays to be viewed as lists.
*
* <p>The methods in this class all throw a {@code NullPointerException},
* if the specified array reference is null, except where noted.
*
* <p>The documentation for the methods contained in this class includes
* brief descriptions of the <i>implementations</i>. Such descriptions should
* be regarded as <i>implementation notes</i>, rather than parts of the
* <i>specification</i>. Implementors should feel free to substitute other
* algorithms, so long as the specification itself is adhered to. (For
* example, the algorithm used by {@code sort(Object[])} does not have to be
* a MergeSort, but it does have to be <i>stable</i>.)
java.util에 속하고, 1.8부터 제공됨. Null 처리를 간편하게 하기 위해서 등장.
T 객체를 포장해주는 래퍼 클래스이고, NullPointerException 예외를 예방할 수 있다.
public final class Optional<T>final 로 정의되어 있어 더 이상 확장이 불가능하다.
Optional의 특이한 점은
아래와 같이 객체를 생성하지 않는다.
new Optional();
아래의 3개의 메소드를 통해 Optional 클래스의 객체를 생성할 수 있다.
데이터가 없는 Optional 객체를 생성하려면 이와 같이 empty() 메소드를 이용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an empty {@code Optional} instance. No value is present for this
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
만약 null이 추가될 수 있는 상황이면 이 메소드를 사용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an {@code Optional} describing the given value, if
* non-{@code null}, otherwise returns an empty {@code Optional}.
* public static <T> Optional<T> ofNullable(T value) {
return value == null ? (Optional<T>) EMPTY
: new Optional<>(value);
}
반드시 데이터가 들어갈 수 있는 상황에는 of() 메소드를 사용한다.
javadoc에는 아래와 같이 기술되어 있다.
* Returns an {@code Optional} describing the given non-{@code null}
* value.
public static <T> Optional<T> of(T value) {
return new Optional<>(Objects.requireNonNull(value));
}
아래의 메소드는 데이터를 리턴하는 메소드들이다.
가장 많이 사용되는메소드이다. 만약 데이터가 없을 경우에는 null이 리턴된다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise throws
* {@code NoSuchElementException}.
*
* @apiNote
* The preferred alternative to this method is {@link #orElseThrow()}.
*
* @return the non-{@code null} value described by this {@code Optional}
* @throws NoSuchElementException if no value is present public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
만약 값이 없을 경우에는 orElse() 메소드를 사용하여 기본값을 지정할 수 있다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise returns
* {@code other}.
*
* @param other the value to be returned, if no value is present.
* May be {@code null}.
* @return the value, if present, otherwise {@code other}
*/ public T orElse(T other) {
return value != null ? value : other;
}
Supplier<T>라는 인터페이스를 활용하는 방법으로 orElseGet()을 사용할 수 있다.
javadocs에는 아래와 같이 기술되어 있다.
* If a value is present, returns the value, otherwise returns the result
* produced by the supplying function.
*
* @param supplier the supplying function that produces a value to be returned
* @return the value, if present, otherwise the result produced by the
* supplying function
* @throws NullPointerException if no value is present and the supplying
* function is {@code null}
*/ public T orElseGet(Supplier<? extends T> supplier) {
return value != null ? value : supplier.get();
}
만약 여기에도 데이터가 없을 경우에 예외를 발생시키고 싶으면 orElseThrow() 메소드를 사용한다.
* If a value is present, returns the value, otherwise throws
* {@code NoSuchElementException}.
*
* @return the non-{@code null} value described by this {@code Optional}
* @throws NoSuchElementException if no value is present
* @since 10
*/
public T orElseThrow() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
- 일종의 자바 프로젝트 압축 파일
- ZIP 파일 압축 알고리즘을 기반으로 만들어짐 >> 반디집, 알집과 같은 zip 프로그램과 호환 가능
- JAR 파일은 웹브라우저에서 빠르게 다운로드할 수 있도록, 자바 애플릿을 위한 클래스, 이미지 및 사운드 파일들을 하나의 파일에 압축하여 담고 있는 파일이다.
- 사용자의 요청에 의해 웹페이지의 일부로 들어오는 애플릿에는 여러개의 파일들이 담겨 있을 수 있는데, 각각은 웹페이지와 함께 다운로드 되어야 한다. 이 때 그 파일들을 하나의 파일에 압축하면 다운로드에 소요되는 시간이 절약된다.
- 자바로 개발한 여러 클래스 파일들 또는 패키지 파일이 있을 때, 이를 하나로 묶으면 그 클래스들을 참조하기도 편하고, 다운 받기도 쉽다.
- 자바 어플리케이션 프로그램을 개발 후 하나의 파일로 묶어서 실행하게 해준다.
- JAR 로 묶어서 배포하게 되면, 경로나 파일의 위치에 상관없이 프로그램의 실행이 가능하다.
옵션들
a) -client:
자바 HotSpot Client VM을 선택한다. (디폴트 값이다)
b) -server:
자바 HotSpot Server VM을 선택한다.
c) -classpath (-cp):
참조할 클래스 파일 패스를 지정하는데, jar파일, zip파일, 클래스파일의 디렉터리 위치를 기술한다.
각 클래스파일 패스는 콜론(:)을 통해서, 분리시켜 기술한다
자바VM은 자바프로그램을 로딩시, -classpath로 지정된 클래스 패스나, java플래폼이 설치된, 운영체제에서의
환경변수로 지정된, 클래스패스를 통해서, 클래스 파일들을 참조하게 된다.
d) -D <property name>=<property value>:
시스템의 property 값을 설정한다.
ex) java -Djava.library.path=. HelloWorld
자바의 시스템 property(속성)중 "java.library.path"값을 "." (현재디렉터리)로 지정해서, HelloWorld 실행시켜라는 의미 이다.
위와같이 자바VM에 지정된 속성을 실행시 -D옵션을 사용해서, 변경, 지정할수 있다.
e) -jar 파일이름:
jar파일로 압축되어져 있는 자바 프로그램을 실행시킨다.
클래스 파일이름 대신 jar파일을 사용해서, 압축되어져 있는 자바 프로그램을 실행시킬수 있는데, 위프로그램이 제대로 실행되어지기 위해서, Jar파일안의 manifest라는 텍스트 파일에 Main-Class:classname 같은 형태의 텍스트 라인이 포함되어 있어야 한다.
그리고, 여기에 기술된 classname은 main함수를 포함하고 있는 클래스 이름이 되어야 한다.
f) -verbose:
자바프로그램 실행되어지는 정보를 화면에 출력해준다.
-verbose:class
로딩되어지는 각클래스들의 정보를 화면에 출력한다.
-verbose:gc
garbage collection 이벤트를 화면에 출력한다.
-verbose:jni
native 함수들과 다른 자바 native 인터페이스 사용에 대한 정보를 출력한다
g) -version:
현재 JVM의 버젼 정보만 출력한다
h) -showversion:
현재 JVM의 버젼정보를 출력한다.
java -showversion HelloWolrd
와 같이 자바 프로그램을 실행시키면서, 자바 버젼정보를 출력할수 있다.
i) -X
비표준 자바옵션 리스트를 화면에 출력해준다.
-Xms, -Xmx
자바를 구동시, JVM이 사용가능한 최대 메모리 사이즈를 변경합니다.
JVM이 자바프로그램을 구동하기 위해, 초기설정된 메모리사이즈는 64M입니다.
사용방법은 다음과 같습니다
java -Xms <초기힙사이즈> -Xmx <최대힙사이즈>
예를들어, Hello.class 자바 프로그램을 시작시, 256M(메가)의 힙사이즈를 할당하며, 최대 512M의 힙사이즈를 할당받고 싶다면, 다음과같이 합니다.
java -Xms256m -Xmx512m Hello
-XX:PermSize, -XX:MaxPermSize
클래스 메타 정보 메모리 (Xms, Xmx 메모리와 별도로 관리된다.
-XX:PermSize=64m -XX:MaxPermSize=256m
클래스패스란 말 그대로 클래스를 찾기위한 경로이다.
자바에서 클래스패스의 의미도 똑같다.
즉, JVM이 프로그램을 실행할 때, 클래스파일을 찾는 데 기준이 되는 파일 경로를 말하는 것이다.
소스 코드(.java로 끝나는 파일)를 컴파일하면 소스 코드가 “바이트 코드”(바이너리 형태의 .class 파일)로 변환된다.
java runtime(java 또는 jre)으로 이 .class 파일에 포함된 명령을 실행하려면, 먼저 이 파일을 찾을 수 있어야 한다.
이때 .class 파일을 찾을 때 classpath에 지정된 경로를 사용한다. classpath는 .class 파일이 포함된 디렉토리와 파일을 콜론으로 구분한 목록이다.
java runtime은 이 classpath에 지정된 경로를 모두 검색해서 특정 클래스에 대한 코드가 포함된 .class 파일을 찾는다. 찾으려는 클래스 코드가 포함된 .class 파일을 찾으면 첫 번째로 찾은 파일을 사용한다.
classpath를 지정할 수 있는 두 가지 방법이 있다.
하나는 환경 변수 CLASSPATH를 사용하는 방법이고, 또 하나는 java runtime에 -classpath 플래그를 사용하는 방법이다.
아래와 같이 컴파일할 때나 실행할 때 다음과 같이 추가해줘야 한다.
$ java -classpath ~
$ java -cp ~
일반적인 클래스 패스의 환경 변수 이름은 CLASSPATH라고 지정한다.
컴파일 할 때 알아두면 좋은 옵션
-d : javac는 클래스가 있는 디렉터리에 클래스 파일을 생성. 이 옵션을 제공하면, 해당 디렉터리도 생성하고, 관련된 패키지 디렉터리도 생성하여 클래스 파일을 만들어준다.
-deprecation : deprecated 된 클래스에 대한 상세한 정보를 포함하여 컴파일한다.
-g : 디버깅과 관련된 정보를 포함한 클래스 파일을 생성.
자바의 표준 실행 옵션
-client : 클라이언트 VM을 사용한다. Swing과 같이 클라이언트 UI를 처리할 때 유용
-server : 서버 "VM"을 사용함
-cp 혹은 -classpath : 클래스 패스를 지정할 때 사용하며, 이 옵션의 공백 뒤에 경로를 연달아 지정하면 된다.
-verbose : 클래스가 JVM에 로딩되는 정보를 출력함
-verbosegc : gc가 발생하는 정보를 출력한다.
-version : JVM의 버전을 출력하고 프로세스를 종료한다
-showversion : JVM의 버전을 출력하고 자바 프로세스를 계속 수행한다.
-d32 : 가능한 경우 32비트 데이터 모델을 사용한다.
-d64 : 가능한 경우 64비트 데이터 모델을 사용함
-Xms : JVM의 시작 크기를 지정함
-Xmx : JVM의 최대 크기를 지정함.
-Xss : 스레드의 스택 크기를 지정함. StackOverflowError가 발생할 때 이 옵션을 지정하여 스택의 크기를 증가시킬 수 있다.
다양한 상황에서 원하는 형태로 출력을 도와주는 클래스
숫자와 통화를 나타내기 위한
NumberFormat
날짜와 시간을 간단히 표현하려면
DateFormat
SimpleDateFormat
문자열을 쉽게 처리하기 위한
MessageFormat
C언어 같은 형식의 문자열 처리
Formatter
java.lang 다음으로 많이 쓰인다.
알아두면 유용한 클래스들
- Date, Calendar
- Collections : Collection 인터페이스를 구현한 클래스에 대한 객체생성, 정렬, 병합, 검색 등의 기능을 안정적으로 수행하도록 도와주는 역할
- Arrays : 배열을 다루기 위한 유틸 클래스
- binarySearch() 메소드 : 메소드는 전달받은 배열에서 특정 객체의 위치를 이진 검색 알고리즘을 사용하여 검색한 후, 해당 위치를 반환합니다.
- copyOf() 메소드 : 전달받은 배열의 특정 길이만큼을 새로운 배열로 복사하여 반환
- copyOfRange() 메소드 : 전달받은 배열의 특정 범위에 해당하는 요소만을 새로운 배열로 복사하여 반환
- fill() 메소드 :fill() 메소드는 첫 번째 매개변수로 초기화할 배열을 전달받고, 두 번째 매개변수로 초기값을 전달받습니다.
- 따라서 이 메소드는 전달받은 원본 배열의 값을 변경
- sort() 메소드 : 매개변수로 정렬할 배열을 전달받으며, 따라서 이 메소드는 전달받은 원본 배열의 순서를 변경
- StringTokenizer : 긴 문자열을 지정된 구분자(delimiter)를 기준으로 토큰(Token)이라는 여러 개의 문자열로 잘라내는 데 사용
- Properties :
- MAP 계열의 컬렉션 프레임워크와 비슷하게 동작하는 파일
- "Key = Value" 형태로 된 "파일이름.properties" 파일 또는 Xml 파일
- key를 주면 Value를 반환하는 기능을 가짐
- DB의 연결정보 등을 저장해두는 용도로 많이 쓰임
- Random
- Formatter : Java 언어에서는 Formatter 클래스를 제공하여 원하는 형태로 출력을 지정할 수 있습니다. Formatter 클래스는 다양한 출력에 사용할 수 있는데 여기에서는 출력에 사용할 문자열을 만드는 방법에 관해서만 다루고 있습니다. 출력 포멧을 정하는 방법은 앞에서 소개한 String 클래스의 format 메서드의 포멧 지정자와 같은 방법입니다.
- %[index$][flags][width]type
blocking/non-blocking
이 그룹은 호출되는 함수가 바로 return하느냐 마느냐 (바로 제어권이 갔다오냐)가 관심사이다.
동기/비동기
이 그룹은 호출되는 함수의 callback을 통해 순서를 보장하는지가 관심사이다.
