/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
* The general contract of {@code hashCode} is:
* <ul>
* <li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* This integer need not remain consistent from one execution of an
* application to another execution of the same application.
* <li>If two objects are equal according to the {@code equals(Object)}
* method, then calling the {@code hashCode} method on each of
* the two objects must produce the same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link java.lang.Object#equals(java.lang.Object)}
* method, then calling the {@code hashCode} method on each of the
* two objects must produce distinct integer results. However, the
* programmer should be aware that producing distinct integer results
* for unequal objects may improve the performance of hash tables.
* </ul>
* <p>
* As much as is reasonably practical, the hashCode method defined by
* class {@code Object} does return distinct integers for distinct
* objects. (This is typically implemented by converting the internal
* address of the object into an integer, but this implementation
* technique is not required by the
* Java™ programming language.)
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/
public native int hashCode();
의역을 해보면, 해시테이블 같은 컬렉션을 사용할 때 이점을 위해 제공되고,
hashCode은 아래의 규칙을 따라야 한다.
1. 런타임 동안 hashCode는 항상 같은 값을 리턴해야함.
2. equals 메소드가 같다고 판단한 두 객체의 hashCode 호출 결과는 같은 값을 리턴해야 함.
3. 그러나 equals 메소드가 다르다고 판단한 두 객체의 hashCode값이 반드시 달라야 하는 것은 아님 (같을 수도 있음)
(단, hashCode값이 다르면 해시테이블의 성능은 향상된다.) -> 왜냐하면 해시테이블은 hashCode()를 기반으로 버킷을 저장하기 때문에, equals 다른데 hashCode()가 같으면 해시 충돌이 발생하여, 같은 버킷에 리스트나 트리를 통해 저장하기 때문에, 그 만큼의 비효율이 발생함.
즉 equals가 true이면 hashCode는 같아야 하고
equlas가 false이면 같아도 되고, 달라도 된다.
hashcode와 equals와의 관계
hashCode()와 equals를 같이 override해야 하는 이유
hash값을 사용하는 Collection은 객체가 논리적으로 같은지 비교할 때 아래 그림과 같은 과정을 거친다.
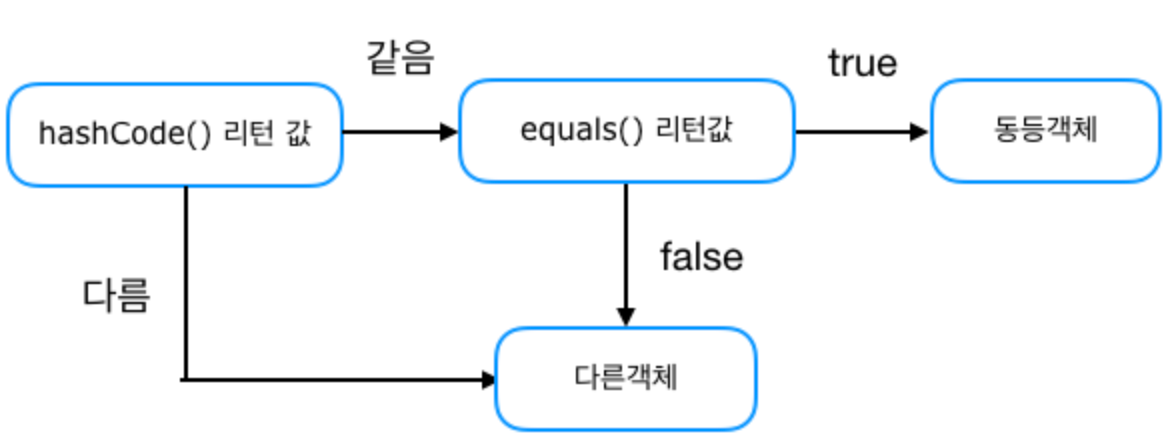
hashCode값이 같은지 판단하고, equals를 비교하여 true이면 동등한 객체라도 판단한다.
하지만 hashCode값을 오버라이드 하지 않으면, 객체의 고유한 값을 리턴하기 때문에, 객체마다 다른 값을 리턴한다.
그래서 equals를 동등성이 보장되게끔 오버라이드 하면 hashCode() 함수도 동등성이 보장되게 끔 오버라이드 해야한다.
+ equals()가 true일 때 hashCode()는 같은 값을 리턴해야 하므로, equals()를 오버라이드 하면 hashCode()도 오버라이드 해야한다.
+ hashCode()를 오버라이드 하지 않았을 때 어떤 값을 반환하는가?
java -XX:+PrintFlagsFinal | grep hashCode
0 == Lehmer random number generator,
1 == "somehow" based on memory address
2 == always 1
3 == increment counter
4 == memory based again ("somehow")
5 == read below자바에 총 5개의 옵션이 존재하고 위와 같이 명령어를 통해 현재 JVM에 어떤 옵션으로 설정되어 있는지 확인할 수 있다.
그리고 hotspot의 jvm.cpp파일에서 JVM_IHashCode는 ObjectSynchorinzer::FastHashCode를 사용하고 있고, 새로운 해시 코드 할당은 get_next_hash 함수를 사용한다.
아래는 get_next_hash이다.
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0 ;
if (hashCode == 0) {
// This form uses an unguarded global Park-Miller RNG,
// so it's possible for two threads to race and generate the same RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random() ;
} else
if (hashCode == 1) {
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addrBits = intptr_t(obj) >> 3 ;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;
} else
if (hashCode == 2) {
value = 1 ; // for sensitivity testing
} else
if (hashCode == 3) {
value = ++GVars.hcSequence ;
} else
if (hashCode == 4) {
value = intptr_t(obj) ;
} else {
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = Self->_hashStateX ;
t ^= (t << 11) ;
Self->_hashStateX = Self->_hashStateY ;
Self->_hashStateY = Self->_hashStateZ ;
Self->_hashStateZ = Self->_hashStateW ;
unsigned v = Self->_hashStateW ;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;
Self->_hashStateW = v ;
value = v ;
}위의 코드를 해석해보면 다음과 같다.
0 : 글로벌 랜덤값 생성기.os의 random()을 이용하지만, 경합이 발생할 수 있어, 동일한 hashCode가 생성될 수 있다는 단점.
1 : 객체의 주소값과 랜덤값을 연산하여 hashcode값 생성
2 : 항상 1을 리턴한다. (디버깅과 테스트 목적)
3 : 자동으로 증가하는 숫자를 이용한다 (디버깅과 테스트 목적이고, Global한 카운터가 사용되서, 경합이 발생할 수 있다.)
4 : 32비트로 trim된 객체의 주소값
5 : 로컬 스레드의 xor-shift 랜덤 생성기를 사용함 (java8의 디폴트 값)
intx hashCode = 5자바8 기준으로 5로 세팅된 것을 확인할 수 있다.
출처 :
stackoverflow.com/questions/2237720/what-is-an-objects-hash-code-if-hashcode-is-not-overridde
'개발 > Java' 카테고리의 다른 글
| java.util.collections 총정리 set편 (0) | 2021.05.13 |
|---|---|
| Lombok 이란? (0) | 2021.05.12 |
| mixin이란 (0) | 2021.05.11 |
| 자바 스레드 덤프 Thread Dump 분석 (1) | 2021.04.26 |
| 힙덤프 (0) | 2021.04.16 |
